项目概述
OmniParser 是微软研究院开发的一个创新项目,旨在增强大型视觉语言模型(如 GPT-4V)在操作图形用户界面(GUI)时的能力。
该项目由微软研究院和微软通用 AI 团队共同开发。
https://microsoft.github.io/OmniParser/
核心问题与解决方案
传统视觉语言模型在处理 GUI 操作时面临两个主要挑战:
- 难以可靠识别界面中的可交互图标
- 难以准确理解截图中各元素的语义并将预期操作与屏幕区域关联
OmniParser 通过以下方式解决这些问题:
- 开发了专门的交互式图标检测数据集
- 设计了针对性的模型微调方案
- 提供了结构化的界面元素解析方法
OmniParser 项目包含两个重要的数据集:
- 可交互图标检测数据集:
- 包含 67,000 个独特的截图样本
- 基于 DOM 树标注的边界框标签
- 来源于 clueweb 数据集中的 100,000 个流行网页 URL
- 图标描述数据集:
- 包含 7,000 对图标-描述配对数据
- 用于微调说明模型
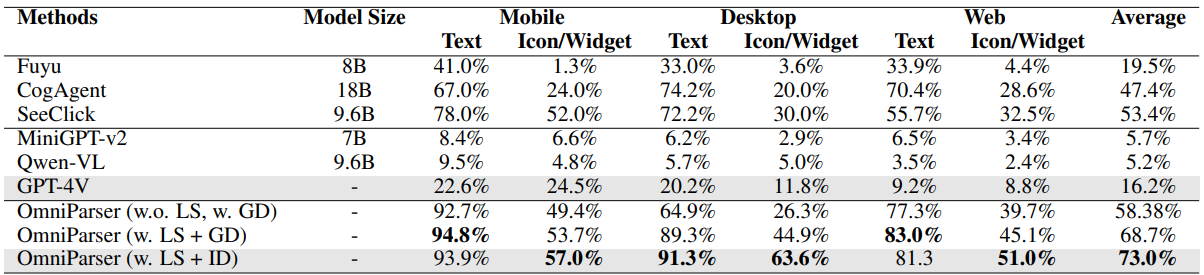
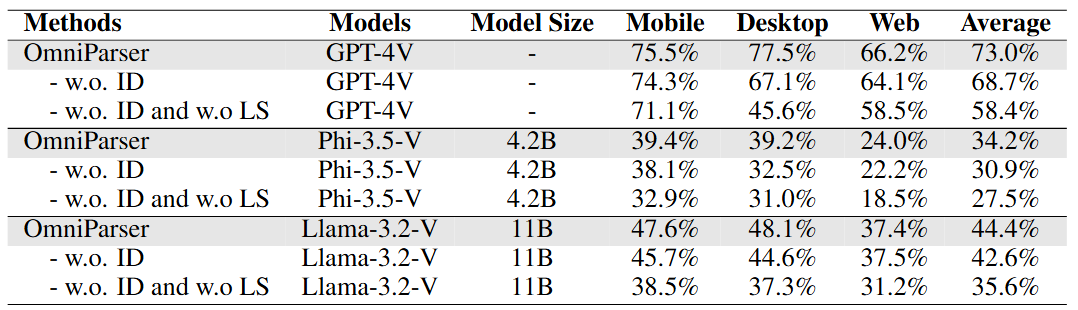
性能优势
OmniParser 在多个基准测试中都展现出优秀表现:
- SeeClick 基准测试
- Mind2Web 基准测试
- AITW 基准测试
特别值得注意的是,仅使用截图输入的 OmniParser 性能超过了需要额外信息的 GPT-4V 基线模型。
OmniParser 可以作为插件与多个视觉语言模型配合使用:
- GPT-4V
- Phi-3.5-V
- Llama-3.2-V
![]()
![]()
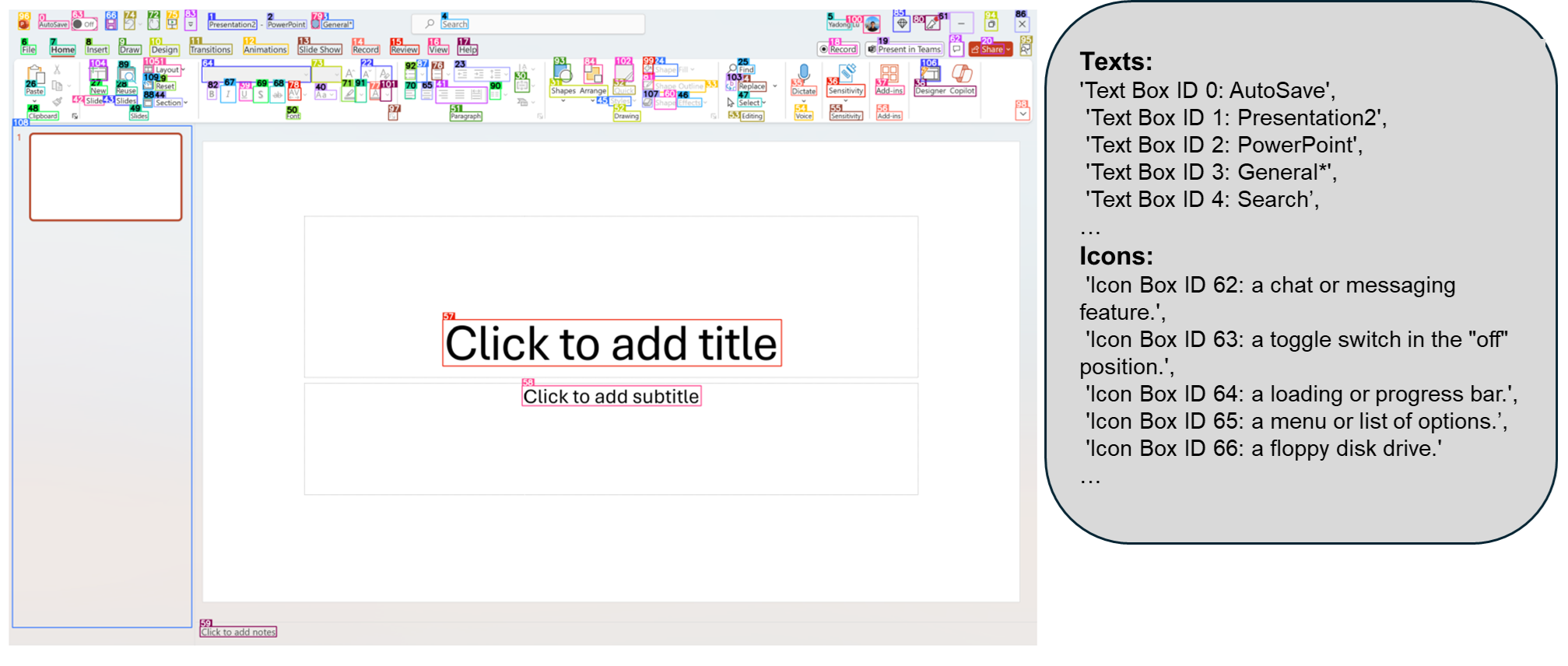
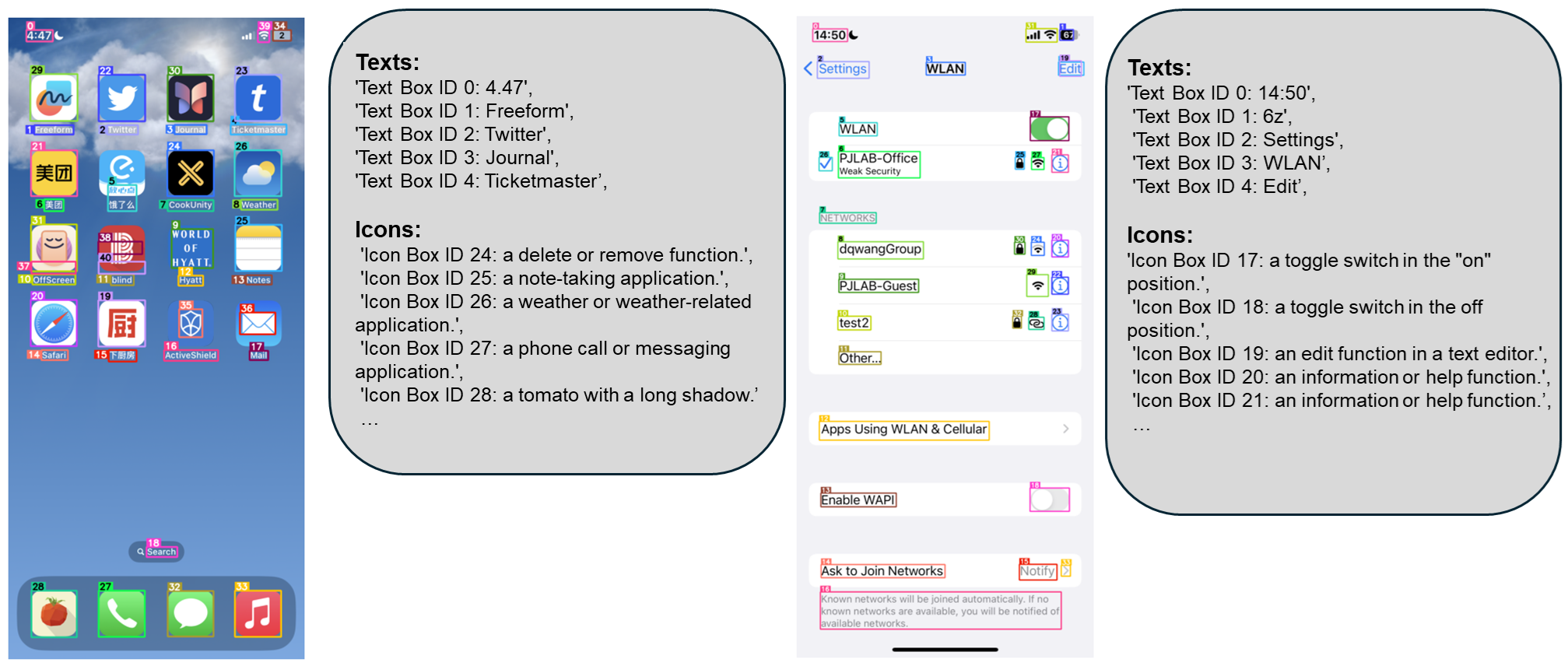
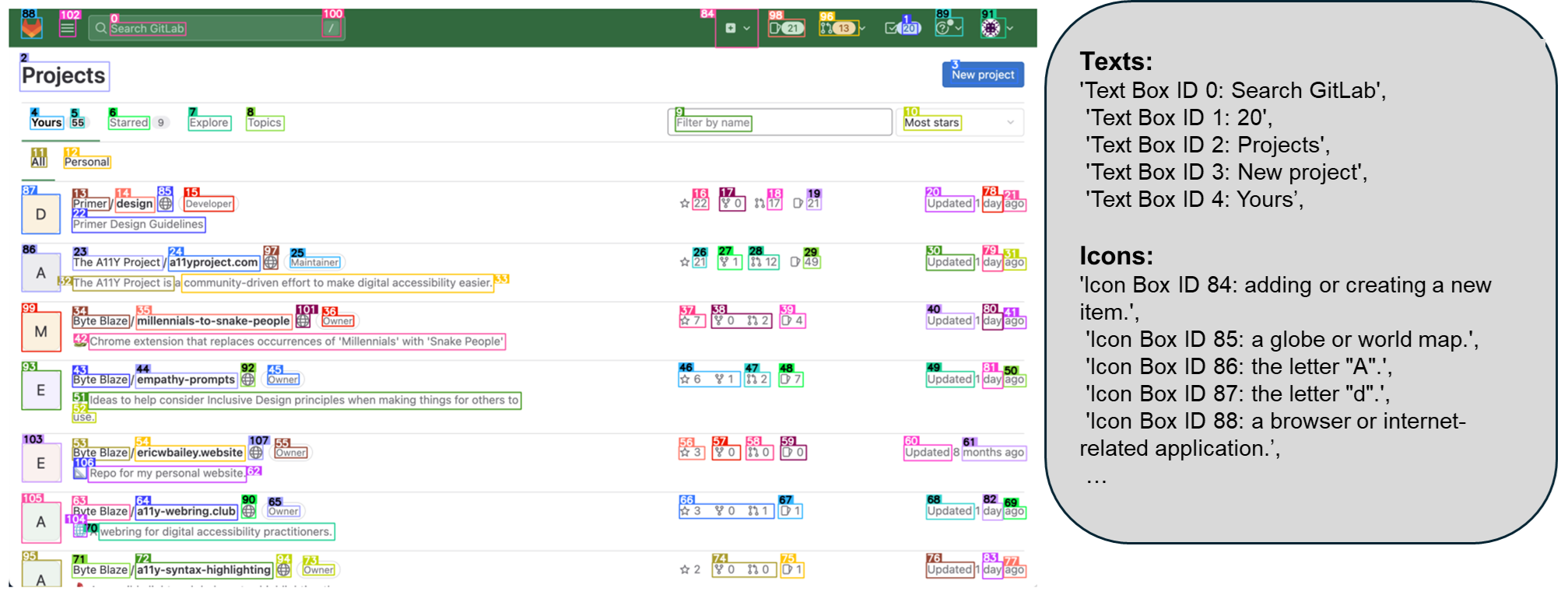
工作流程
OmniParser 的处理流程包括:
- 输入:
- 用户任务描述
- UI 截图
- 输出:
- 解析后的截图(包含边界框和数字 ID 标注)
- 局部语义信息(包含提取的文本和图标描述)
安装、运行
安装
1
2
3
conda create -n "omni" python==3.12
conda activate omni
pip install -r requirements.txt
模型下载:
地址:https://huggingface.co/microsoft/OmniParser
把文件放在weights/目录下
目录结构: weights/icon_detect, weights/icon_caption_florence, weights/icon_caption_blip2.
模型转换:
1
python weights/convert_safetensor_to_pt.py
运行程序:
1
python gradio_demo.py