
大家好,我是 Ai 学习的章北海。
有段日子没有更新机器学习系列了
最近在大量使用大模型写代码、写文章、写论文、做图表。
尤其是直接用大模型生成SVG图表,Claude-3.7表现极佳。
[[250226 实测,阿里最新Qwen2.5-max可否与DeepSeek一战?结果统统被Claude-3.7碾压]]
比如下面这张图,你敢相信这是大模型直接绘制的吗?

不忘本,今天更新一篇机器学习相关的内容。
图表及文字均由Claude-3.7撰写,主题涵盖了机器学习项目的全景了解、制定高效的学习计划、机器学习面试准备的路线图以及数据科学项目团队中各角色的职责。这些内容对应了初学者从了解机器学习领域、系统性学习、为求职做准备到实际参与项目工作的四个关键流程,为学习者提供了从入门到实践的全方位指导
1、了解机器学习项目全景
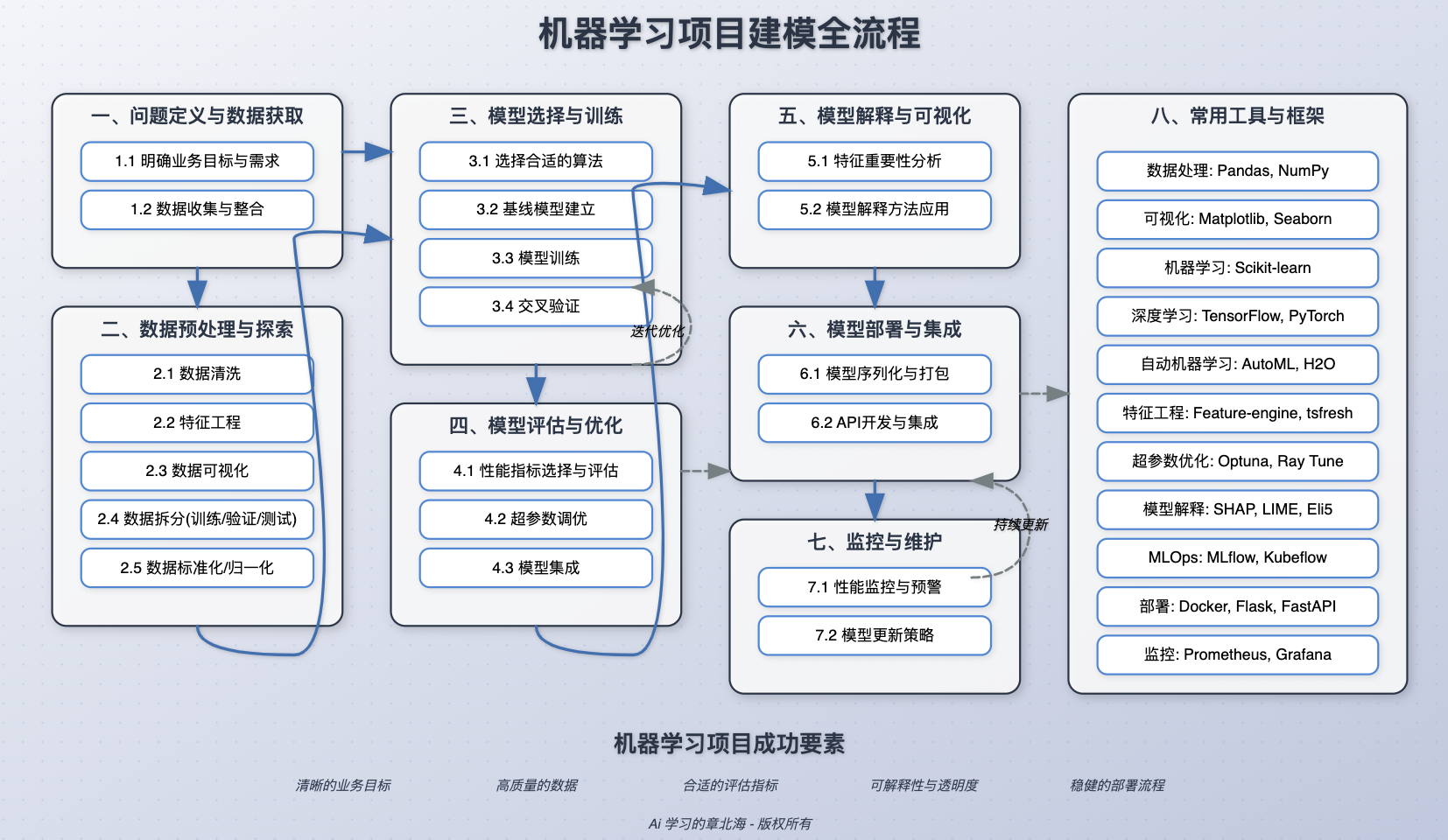
分为八个主要阶段,每个阶段包含若干关键步骤:
-
问题定义与数据获取
- 明确业务目标与需求:确定项目的具体目标和解决的问题
- 数据收集与整合:从各种来源收集相关数据并整合
-
数据预处理与探索
- 数据清洗:处理缺失值、异常值和重复数据
- 特征工程:创建、转换和选择相关特征
- 数据可视化:使用图表分析数据分布和关系
- 数据拆分:将数据集分为训练集、验证集和测试集
- 数据标准化/归一化:统一数据尺度
-
模型选择与训练
- 选择合适的算法:根据问题类型选择算法
- 基线模型建立:构建简单模型作为基准
- 模型训练:使用训练数据训练模型
- 交叉验证:评估模型的稳定性和泛化能力
-
模型评估与优化
- 性能指标选择与评估:选择合适的指标评估模型表现
- 超参数调优:优化模型参数以提高性能
- 模型集成:结合多个模型以获得更好的预测结果
-
模型解释与可视化
- 特征重要性分析:理解哪些特征对模型影响最大
- 模型解释方法应用:应用SHAP、LIME等解释技术
-
模型部署与集成
- 模型序列化与打包:将模型转换为可部署格式
- API开发与集成:开发接口使模型可供其他系统调用
-
监控与维护
- 性能监控与预警:跟踪模型在生产环境中的表现
- 模型更新策略:制定模型定期更新的策略
-
常用工具与框架
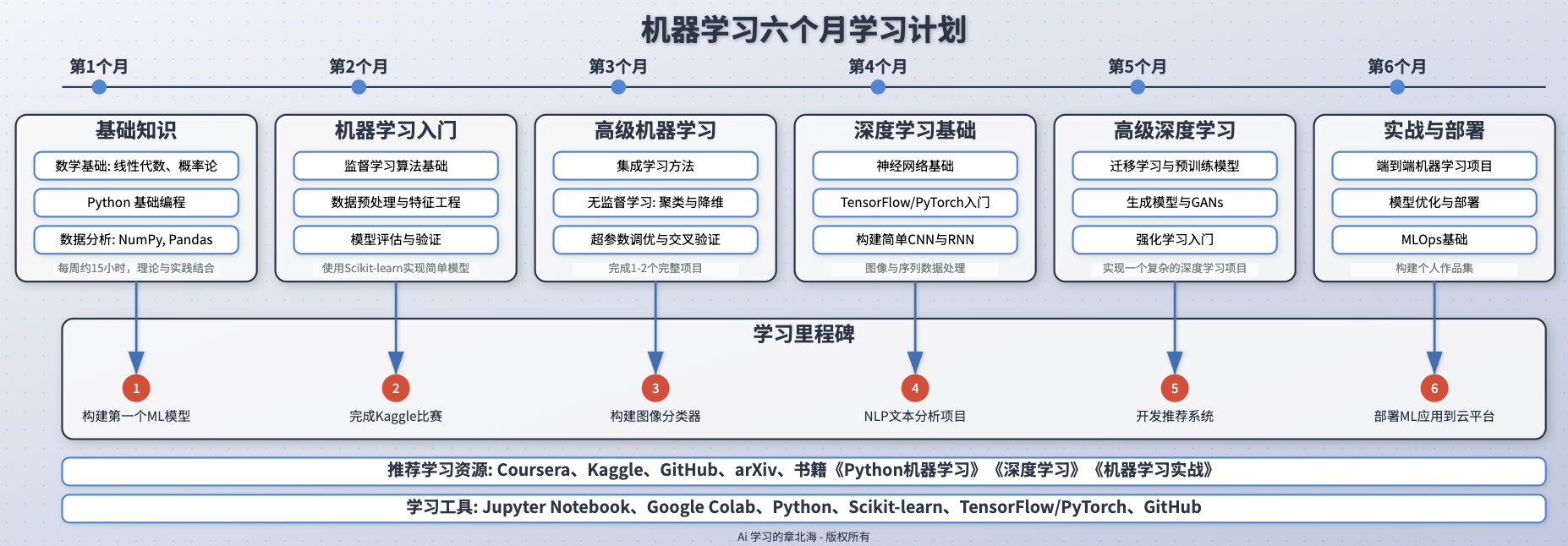
三个主要部分:月度学习内容、学习里程碑和学习资源工具。
-
第1个月:基础知识
- 数学基础:线性代数、概率论
- Python基础编程
- 数据分析:NumPy, Pandas
- 建议:每周约15小时,理论与实践结合
-
第2个月:机器学习入门
- 监督学习算法基础
- 数据预处理与特征工程
- 模型评估与验证
- 建议:使用Scikit-learn实现简单模型
-
第3个月:高级机器学习
- 集成学习方法
- 无监督学习:聚类与降维
- 超参数调优与交叉验证
- 建议:完成1-2个完整项目
-
第4个月:深度学习基础
- 神经网络基础
- TensorFlow/PyTorch入门
- 构建简单CNN与RNN
- 建议:图像与序列数据处理
-
第5个月:高级深度学习
- 迁移学习与预训练模型
- 生成模型与GANs
- 强化学习入门
- 建议:实现一个复杂的深度学习项目
-
第6个月:实战与部署
- 端到端机器学习项目
- 模型优化与部署
- MLOps基础
- 建议:构建个人作品集
图表中间部分展示了六个关键里程碑,每个里程碑与对应月份的学习内容相连接:
- 构建第一个ML模型
- 完成Kaggle比赛
- 构建图像分类器
- NLP文本分析项目
- 开发推荐系统
- 部署ML应用到云平台
图表底部提供了两条重要信息:
- 推荐学习资源:Coursera、Kaggle、GitHub、arXiv、书籍《Python机器学习》《深度学习》《机器学习实战》
- 学习工具:Jupyter Notebook、Google Colab、Python、Scikit-learn、TensorFlow/PyTorch、GitHub
3、机器学习面试准备路线图
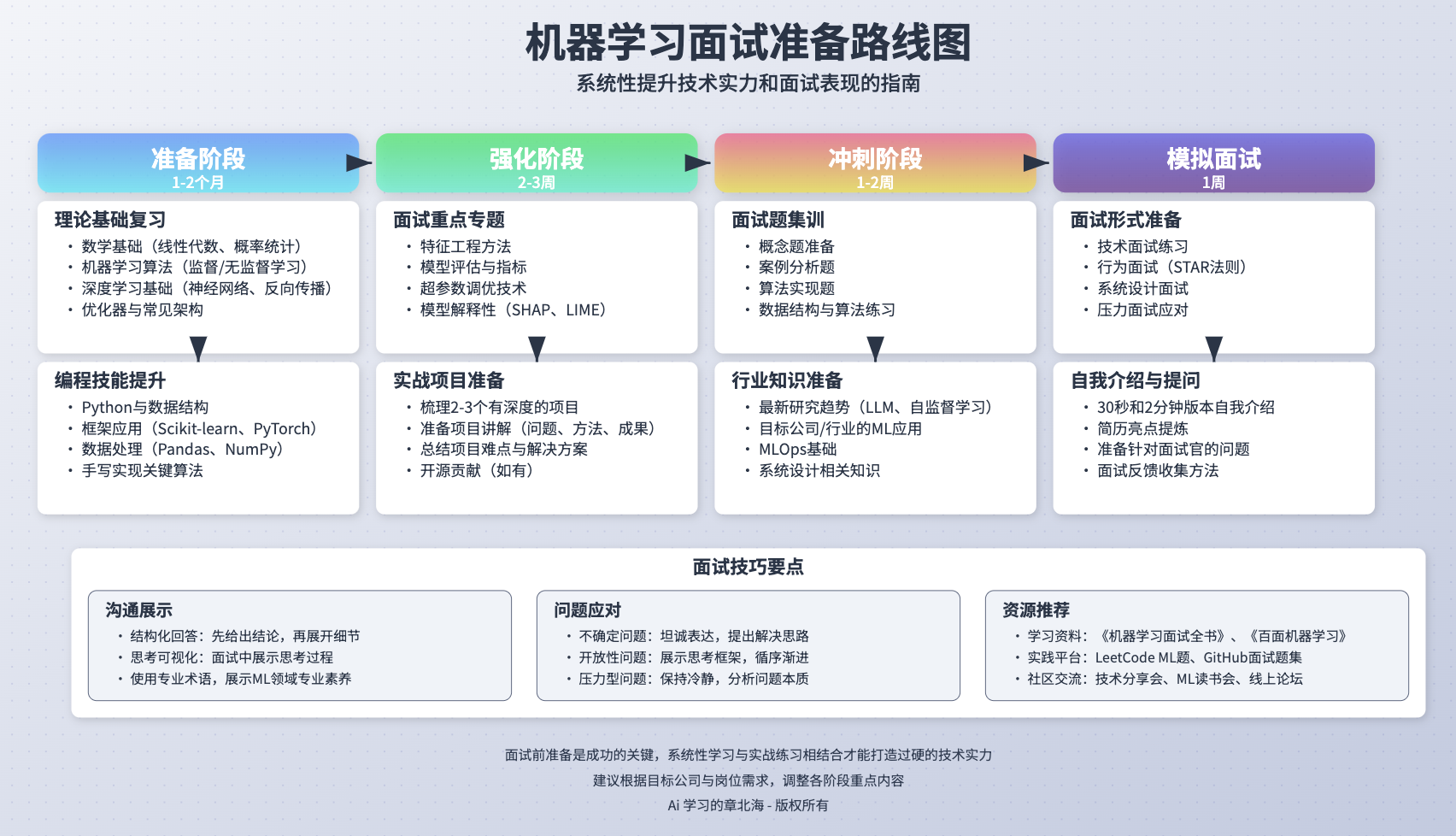

## 准备阶段(1-2个月)
理论基础复习
- 数学基础:线性代数、概率统计、微积分
- 机器学习算法:
- 监督学习:线性回归、逻辑回归、决策树、随机森林、SVM、KNN
- 无监督学习:K-means、层次聚类、PCA、t-SNE
- 集成方法:Bagging、Boosting、Stacking
- 深度学习基础:
- 神经网络原理
- 反向传播算法
- 优化器(SGD、Adam、RMSprop)
- 常见架构(CNN、RNN、LSTM、Transformer)
编程技能提升
- Python编程:熟练掌握数据结构、算法复杂度分析
- 框架应用:Scikit-learn、TensorFlow/PyTorch、Keras
- 数据处理:Pandas、NumPy、数据清洗与预处理
- 算法实现:手写关键算法(如梯度下降、决策树)
强化阶段(2-3周)
面试重点专题
- 特征工程:特征选择、提取和变换方法
- 模型评估:交叉验证、过拟合与欠拟合、各类评估指标
- 超参数调优:网格搜索、随机搜索、贝叶斯优化
- 模型解释性:SHAP值、LIME、特征重要性分析
实战项目准备
- 个人项目梳理:准备2-3个有深度的项目
- 问题背景
- 数据处理方法
- 模型选择理由
- 实现难点与解决方案
- 效果评估与业务价值
- 开源贡献:如有GitHub贡献,准备相关讲解
冲刺阶段(1-2周)
面试题集训
- 基础概念题:准备简洁、准确的解释
- 案例分析题:熟悉常见业务场景的解决方案
- 实现算法题:白板编程练习,如实现KNN、决策树
- 数据结构与算法:排序、搜索、动态规划等经典问题
行业知识准备
- 最新研究趋势:大型语言模型、自监督学习等热点
- 行业应用案例:了解目标公司/行业的ML应用
- MLOps基础:模型部署、监控、A/B测试
模拟面试(1周)
面试形式准备
- 技术面试:算法推导、代码实现、项目讲解
- 行为面试:STAR法则回答问题(情境、任务、行动、结果)
- 系统设计面试:ML系统架构设计
自我介绍与提问
- 简历亮点提炼:30秒和2分钟版本的自我介绍
- 准备问题:针对面试官的有深度问题
面试技巧要点
沟通展示
- 结构化回答:先给出结论,再展开细节
- 思考可视化:面试中展示思考过程,边思考边讲解
- 专业术语使用:准确使用ML术语,展示专业素养
问题应对
- 不确定问题:坦诚表达,提出解决思路
- 开放性问题:展示思考框架,循序渐进分析
- 压力型问题:保持冷静,分析问题本质
资源推荐
学习资料
- 《机器学习面试全书》、《百面机器学习》
- 《深度学习面试宝典》
- Kaggle平台竞赛与讨论区
实践平台
- LeetCode机器学习相关题目
- GitHub上的面试题集合
- 各大公司面经整理
社区交流
- 技术分享会、ML读书会
- 行业研讨会、线上论坛
面试后行动
- 复盘总结面试问题
- 针对性弥补知识漏洞
- 持续学习行业新动态
4、数据科学项目团队角色与职责图
主要是重新拾起了小号【玩机器学习的章北海】,这个号更专注,只聚焦机器学习,目前在更新论文鉴赏系列,主要是流程复现码和文献配图复现。