
先看效果:
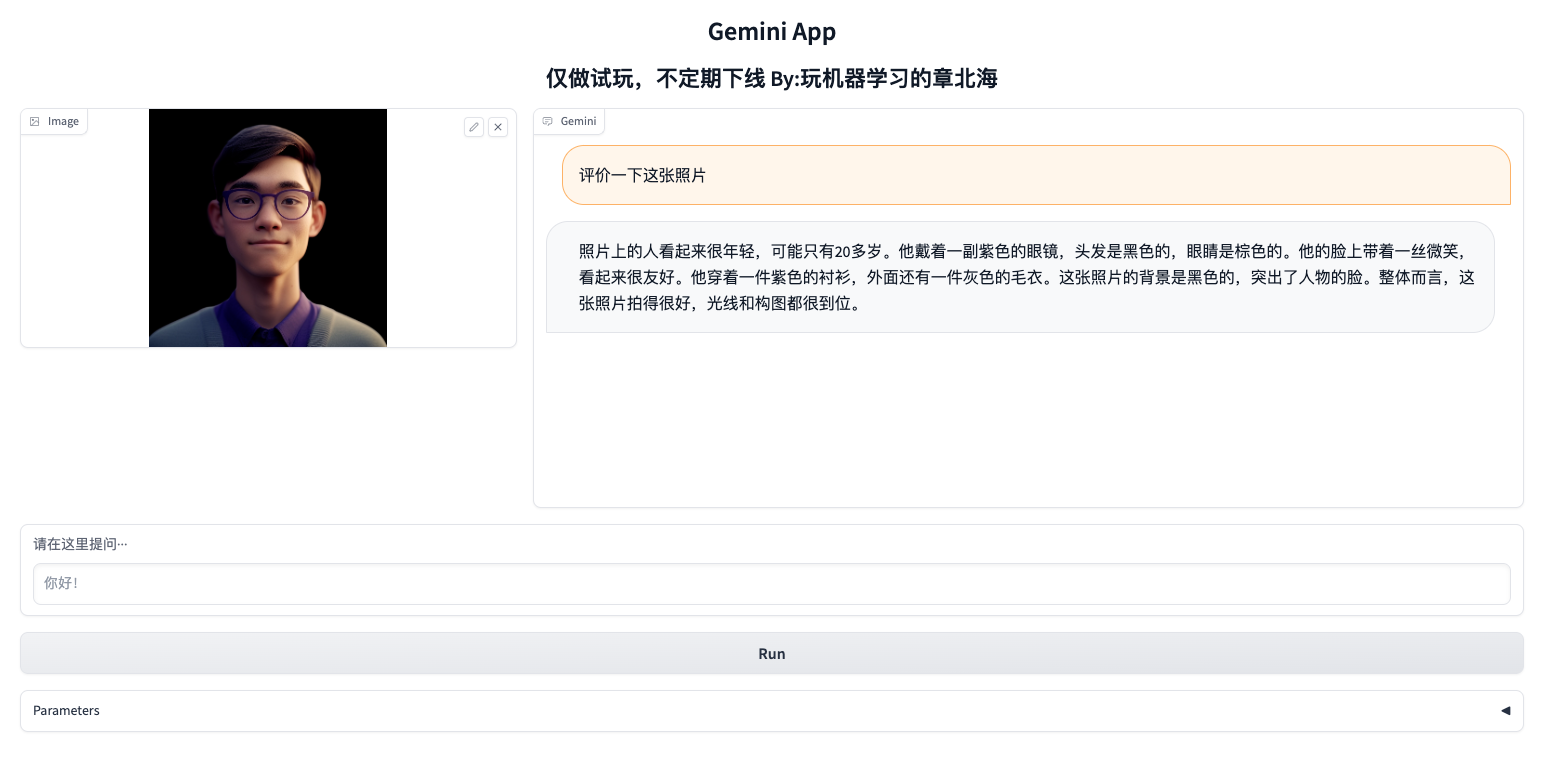
Gemini 是谷歌研发的最新一代大语言模型,目前有三个版本,被称为中杯、大杯、超大杯:
- Gemini Nano(预览访问) 为设备端体验而构建的最高效模型,支持离线使用场景。
- Gemini Pro(已推出) 性能最佳的模型,具有各种文本和图像推理任务的功能。
- Gemini Ultra(预览访问) 将于2024年初推出,用于大规模高度复杂文本和图像推理任务的最强大模型。
其中,Gemini Pro在八项基准测试中的六项上超越了GPT-3.5,被誉为“市场上最强大的免费聊天AI工具”。
本文,我们使用的是 Gemini Pro,Pro有两个模型:
- gemini-pro:针对仅文本提示进行了优化。
- gemini-pro-vision:针对文本和图像提示进行了优化。
如何本地执行脚本 或 开发一个前端页面,顺利白嫖Google的Gemini呢
第一步:去 https://ai.google.dev/ 创建Gemini API key

在这个页面https://makersuite.google.com/app/apikey
点击Create API,然后把api复制出来,保存好,后面要用!

其实,可以去深入学习一下文档:https://ai.google.dev/docs
Gemini 构建应用程序所需的所有信息都可以在这个网站查到,包括Python、Android(Kotlin)、Node.js 和 Swift的支持文档。

我们直接看Python 快速入门指南:
https://ai.google.dev/tutorials/python_quickstart
更省事儿的是直接从这个示例中copy代码:
https://github.com/google/generative-ai-docs/blob/main/site/en/tutorials/python_quickstart.ipynb
核心代码
本地运行脚本,代码其实简单到离谱,6行足矣。
注:网络要畅通
1
2
# 先安装google-generativeai
pip install -q -U google-generativeai
文本对话
1
2
3
4
5
6
import google.generativeai as genai
GOOGLE_API_KEY='这里填写上一步获取的api'
genai.configure(api_key=GOOGLE_API_KEY)
model = genai.GenerativeModel('gemini-pro')
response = model.generate_content("你好")
print(response.text)

图片也可以作为输入,比如让Gemini评价一下我的头像

1
2
3
4
5
6
7
8
9
import PIL.Image
import google.generativeai as genai
img = PIL.Image.open('img.png')
GOOGLE_API_KEY='这里填写上一步获取的api'
genai.configure(api_key=GOOGLE_API_KEY)
model = genai.GenerativeModel('gemini-pro-vision')
response = model.generate_content(["请评价一下这张照片", img])
response.resolve()
print(response.text)

做个网页版
网页版可以使用streamlit或者Gradio实现,Gradio 本公众号写过,包括如何将项目免费部署到huggingface。需要了解更多:可以参考我这篇文章腾讯的这个算法,我搬到了网上,随便玩!
也可以部署到自己的服务器,加个域名就OK了
这里参考了这位大佬的代码:https://github.com/meryemsakin/GeminiGradioApp
我做了中文翻译和GOOGLE_API_KEY获取方式并加了登陆认证
代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
import time
from typing import List, Tuple, Optional
import google.generativeai as genai
import gradio as gr
from PIL import Image
print("google-generativeai:", genai.__version__)
TITLE = """<h1 align="center">Gemini App</h1>"""
SUBTITLE = """<h2 align="center">仅做试玩,不定期下线</h2>"""
GOOGLE_API_KEY='这里填写上一步获取的api'
AVATAR_IMAGES = (
None,
"image.png"
)
def preprocess_stop_sequences(stop_sequences: str) -> Optional[List[str]]:
if not stop_sequences:
return None
return [sequence.strip() for sequence in stop_sequences.split(",")]
def user(text_prompt: str, chatbot: List[Tuple[str, str]]):
return "", chatbot + [[text_prompt, None]]
def bot(
#google_key: str,
image_prompt: Optional[Image.Image],
temperature: float,
max_output_tokens: int,
stop_sequences: str,
top_k: int,
top_p: float,
chatbot: List[Tuple[str, str]]
):
text_prompt = chatbot[-1][0]
genai.configure(api_key=GOOGLE_API_KEY)
generation_config = genai.types.GenerationConfig(
temperature=temperature,
max_output_tokens=max_output_tokens,
stop_sequences=preprocess_stop_sequences(stop_sequences=stop_sequences),
top_k=top_k,
top_p=top_p)
if image_prompt is None:
model = genai.GenerativeModel('gemini-pro')
response = model.generate_content(
text_prompt,
stream=True,
generation_config=generation_config)
response.resolve()
else:
model = genai.GenerativeModel('gemini-pro-vision')
response = model.generate_content(
[text_prompt, image_prompt],
stream=True,
generation_config=generation_config)
response.resolve()
# streaming effect
chatbot[-1][1] = ""
for chunk in response:
for i in range(0, len(chunk.text), 10):
section = chunk.text[i:i + 10]
chatbot[-1][1] += section
time.sleep(0.01)
yield chatbot
image_prompt_component = gr.Image(type="pil", label="Image", scale=1)
chatbot_component = gr.Chatbot(
label='Gemini',
bubble_full_width=False,
avatar_images=AVATAR_IMAGES,
scale=2
)
text_prompt_component = gr.Textbox(
placeholder="你好!",
label="请在这里提问···"
)
run_button_component = gr.Button()
temperature_component = gr.Slider(
minimum=0,
maximum=1.0,
value=0.4,
step=0.05,
label="Temperature",
info=(
"Temperature 控制令牌选择的随机程度 "
"较低的Temperature适用于期望获得真实或正确回答的提示, "
"而较高的Temperature可以导致更多样化或意外的结果 "
))
max_output_tokens_component = gr.Slider(
minimum=1,
maximum=2048,
value=1024,
step=1,
label="Token limit",
info=(
"Token 限制确定每个提示可以获得的最大文本输出量 "
"每个 Token 大约为四个字符,默认值为 2048 "
))
stop_sequences_component = gr.Textbox(
label="Add stop sequence",
value="",
type="text",
placeholder="STOP, END",
info=(
"停止序列是一系列字符(包括空格),如果模型遇到它,会停止生成响应"
"该序列不作为响应的一部分,"
"可以添加多达5个停止序列"
))
top_k_component = gr.Slider(
minimum=1,
maximum=40,
value=32,
step=1,
label="Top-K",
info=(
"Top-k 改变了模型为输出选择 token 的方式 "
"Top-k 为 1 意味着所选 token 在模型词汇表中所有 token 中是最可能的(也称为贪心解码)"
"而 top-k 为 3 意味着下一个 token 从最可能的 3 个 token 中选取(使用temperature)"
))
top_p_component = gr.Slider(
minimum=0,
maximum=1,
value=1,
step=0.01,
label="Top-P",
info=(
"Top-p 改变了模型为输出选择 token 的方式 "
"token 从最可能到最不可能选择,直到它们的概率之和等于 top-p 值 "
"如果 token A、B 和 C 的概率分别为 0.3、0.2 和 0.1,top-p 值为 0.5 "
"那么模型将选择 A 或 B 作为下一个 token(使用temperature) "
))
user_inputs = [
text_prompt_component,
chatbot_component
]
bot_inputs = [
image_prompt_component,
temperature_component,
max_output_tokens_component,
stop_sequences_component,
top_k_component,
top_p_component,
chatbot_component
]
with gr.Blocks() as demo:
gr.HTML(TITLE)
gr.HTML(SUBTITLE)
with gr.Column():
with gr.Row():
image_prompt_component.render()
chatbot_component.render()
text_prompt_component.render()
run_button_component.render()
with gr.Accordion("Parameters", open=False):
temperature_component.render()
max_output_tokens_component.render()
stop_sequences_component.render()
with gr.Accordion("Advanced", open=False):
top_k_component.render()
top_p_component.render()
run_button_component.click(
fn=user,
inputs=user_inputs,
outputs=[text_prompt_component, chatbot_component],
queue=False
).then(
fn=bot, inputs=bot_inputs, outputs=[chatbot_component],
)
text_prompt_component.submit(
fn=user,
inputs=user_inputs,
outputs=[text_prompt_component, chatbot_component],
queue=False
).then(
fn=bot, inputs=bot_inputs, outputs=[chatbot_component],
)
demo.queue(max_size=99).launch(auth=("用户名", "密码"),debug=True)
部署到服务器涉及Nginx配置,域名注册、域名解析等等,蛮麻烦的,这里就不展开了。
