
统计学中的假设检验:Python实现U检验和卡方检验
在数据分析和科学研究中,假设检验是一个非常重要的统计工具。本文将详细介绍两种常用的非参数检验方法:Mann-Whitney U检验(也称为Wilcoxon秩和检验)和卡方检验(Chi-square test),并使用Python来实现这些检验方法。
目录
基础概念
什么是假设检验?
假设检验是一种统计推断方法,用于判断样本数据是否支持某个统计假设。在进行假设检验时,我们通常会设置:
- 原假设(H0):我们想要检验的默认假设
- 备择假设(H1):与原假设相对的另一种可能性
- 显著性水平(α):通常设为0.05,表示我们容忍的犯第一类错误的概率
为什么需要非参数检验?
当数据不满足正态分布或样本量较小时,传统的参数检验(如t检验)可能不适用。这时,我们需要使用非参数检验方法,如U检验和卡方检验。
检验方法的选择
在选择合适的检验方法时,需要考虑以下因素:
- 数据类型
- 定量数据(连续型)
- 定性数据(分类型)
- 等级数据(顺序型)
- 样本特征
- 样本量大小
- 是否独立
- 是否配对
- 组别数量
- 数据分布
- 是否满足正态分布
- 方差是否齐性
- 是否存在异常值
- 检验目的
- 均值比较
- 比例比较
- 相关性分析
- 拟合优度检验
下面是一个简单的检验方法选择决策树:
1
2
3
4
5
6
7
8
9
10
11
数据类型是什么?
├── 定量数据
│ ├── 正态分布
│ │ ├── 两组:t检验
│ │ └── 多组:方差分析
│ └── 非正态分布
│ ├── 两组:Mann-Whitney U检验
│ └── 多组:Kruskal-Wallis检验
└── 定性数据
├── 期望频数≥5:卡方检验
└── 期望频数<5:Fisher精确检验
Mann-Whitney U检验
理论基础
Mann-Whitney U检验是一种非参数检验方法,用于比较两个独立样本的分布是否有显著差异。它不要求数据呈正态分布,适用于序数数据。
Python实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
import numpy as np
from scipy import stats
import matplotlib.pyplot as plt
# 生成示例数据
np.random.seed(42)
group1 = np.random.normal(loc=5, scale=2, size=30)
group2 = np.random.normal(loc=6, scale=2, size=30)
# 执行U检验
statistic, pvalue = stats.mannwhitneyu(group1, group2, alternative='two-sided')
# 可视化
plt.figure(figsize=(10, 6))
plt.boxplot([group1, group2], labels=['组1', '组2'])
plt.title('两组数据的箱线图比较')
plt.ylabel('值')
plt.show()
print(f'U统计量:{statistic}')
print(f'p值:{pvalue}')
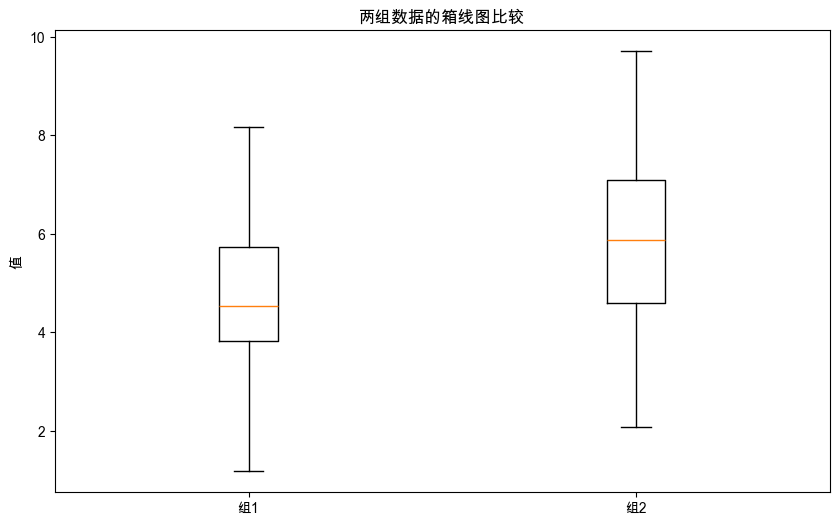 U统计量:293.0
p值:0.020680749139978086
U统计量:293.0
p值:0.020680749139978086
结果解释
- 如果p值 < α(通常为0.05),则拒绝原假设,认为两组数据有显著差异
- 如果p值 ≥ α,则不能拒绝原假设,认为没有足够证据表明两组数据有显著差异
卡方检验
理论基础
卡方检验用于分析分类变量之间是否存在显著关联。它通过比较观察频数与期望频数的差异来判断变量间的独立性。
Python实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
import numpy as np
from scipy.stats import chi2_contingency
import pandas as pd
import seaborn as sns
# 创建示例数据:调查不同年龄段人群的运动习惯
data = np.array([
[30, 20, 10], # 年轻人(经常运动,偶尔运动,很少运动)
[15, 25, 20], # 中年人
[10, 15, 25] # 老年人
])
# 进行卡方检验
chi2, p_value, dof, expected = chi2_contingency(data)
# 创建热力图可视化
plt.figure(figsize=(10, 8))
sns.heatmap(data, annot=True, fmt='d', cmap='YlOrRd',
xticklabels=['经常运动', '偶尔运动', '很少运动'],
yticklabels=['年轻人', '中年人', '老年人'])
plt.title('不同年龄段人群运动习惯分布')
plt.show()
print(f'卡方统计量:{chi2:.2f}')
print(f'p值:{p_value:.4f}')
print(f'自由度:{dof}')
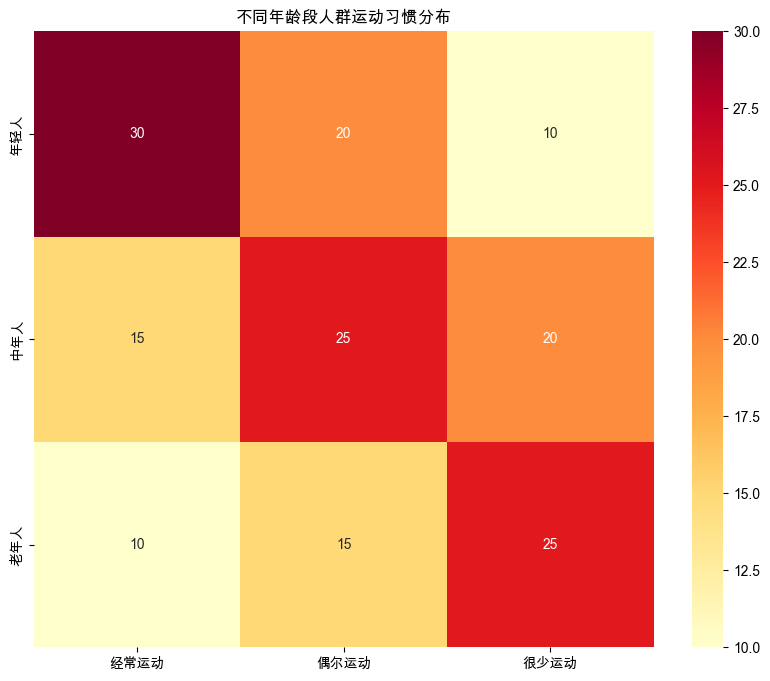 卡方统计量:19.68 p值:0.0006 自由度:4
卡方统计量:19.68 p值:0.0006 自由度:4
结果解释
- 卡方值越大,表示观察值与期望值的差异越大
- p值的解释与上述相同,p < 0.05表示变量间存在显著关联
实际应用案例
案例1:医学研究中的U检验
比较两种治疗方法的效果差异:
1
2
3
4
5
6
7
8
9
10
11
12
# 两组患者的恢复时间(天)
treatment_A = [10, 12, 8, 15, 9, 11, 13, 7, 9, 12]
treatment_B = [14, 16, 12, 18, 13, 15, 17, 11, 13, 16]
# 执行U检验
statistic, pvalue = stats.mannwhitneyu(treatment_A, treatment_B)
print(f'p值:{pvalue:.4f}')
if pvalue < 0.05:
print('两种治疗方法的效果有显著差异')
else:
print('没有足够证据表明两种治疗方法的效果有显著差异')
p值:0.0044 两种治疗方法的效果有显著差异
案例2:市场调研中的卡方检验
分析不同性别对产品偏好的关系:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# 创建列联表
preferences = pd.DataFrame({
'产品A': [150, 100],
'产品B': [120, 130],
'产品C': [80, 120]
}, index=['男性', '女性'])
# 执行卡方检验
chi2, p_value, dof, expected = chi2_contingency(preferences)
print(f'p值:{p_value:.4f}')
if p_value < 0.05:
print('性别与产品偏好存在显著关联')
else:
print('性别与产品偏好没有显著关联')
p值:0.0001 性别与产品偏好存在显著关联
注意事项和建议
- 样本量要求
- U检验:每组至少应有8个观测值
- 卡方检验:每个单元格的期望频数最好大于5
- 数据类型选择
- U检验适用于连续数据或等级数据
- 卡方检验适用于分类数据
- 实践建议
- 在进行检验前,先绘制数据的描述性图表
- 结合实际背景解释统计结果
- 注意检验的假设条件是否满足
总结
本教程详细介绍了U检验和卡方检验的Python实现方法。这些统计工具在实际研究中非常有用,可以帮助我们做出更科学的决策。记住,统计检验只是辅助决策的工具,还需要结合具体情况和专业知识来解释结果。
参考资料
- scipy官方文档:https://docs.scipy.org/doc/scipy/reference/stats.html
- Python统计分析:https://www.statsmodels.org/stable/index.html
- 数据可视化:https://seaborn.pydata.org/