
大家好,我是 Ai 学习的老章
阿里怎么汪峰附体了,总是被强头条呢?
大年初一发布通义千问旗舰版模型 Qwen2.5-Max,并称在指令模型版本性能测试中,几乎全面超越 DeepSeek-V3 等其他模型。
结果被 DeepSeek- R1 的整个春节假期的热度盖的死死的,一点波澜没起。
[[250226 实测,阿里最新Qwen2.5-max可否与DeepSeek一战?结果统统被Claude-3.7碾压]]
3 月 6 日,发布全新推理模型 QwQ-32B,可与具备 6710 亿参数的 DeepSeek-R1 媲美,数学能力、代码能力表现与 DeepSeek-R1 相当,远胜于 o1-mini 及相同尺寸的 R1 蒸馏模型。
结果呢被突然爆火的 Manus 盖住了热度
[[20250306 全网都在吹的Manus,我发现他们创始人更牛逼]] [[250308 V-纯手工复刻Manus演示功能,睡后收入3美分]]

在线体验地址: https://chat.qwen.ai/?models=Qwen2.5-Plus
ModeScope 权重: https://huggingface.co/Qwen/QwQ-32B
HuggingFace 权重: https://modelscope.cn/models/Qwen/QwQ-32B
Blog: https://qwenlm.github.io/blog/qwq-32b
看阿里官方提供的性能表现,QwQ-32B 确实很能打,在几个基准中脚踢 R1,拳打 o1
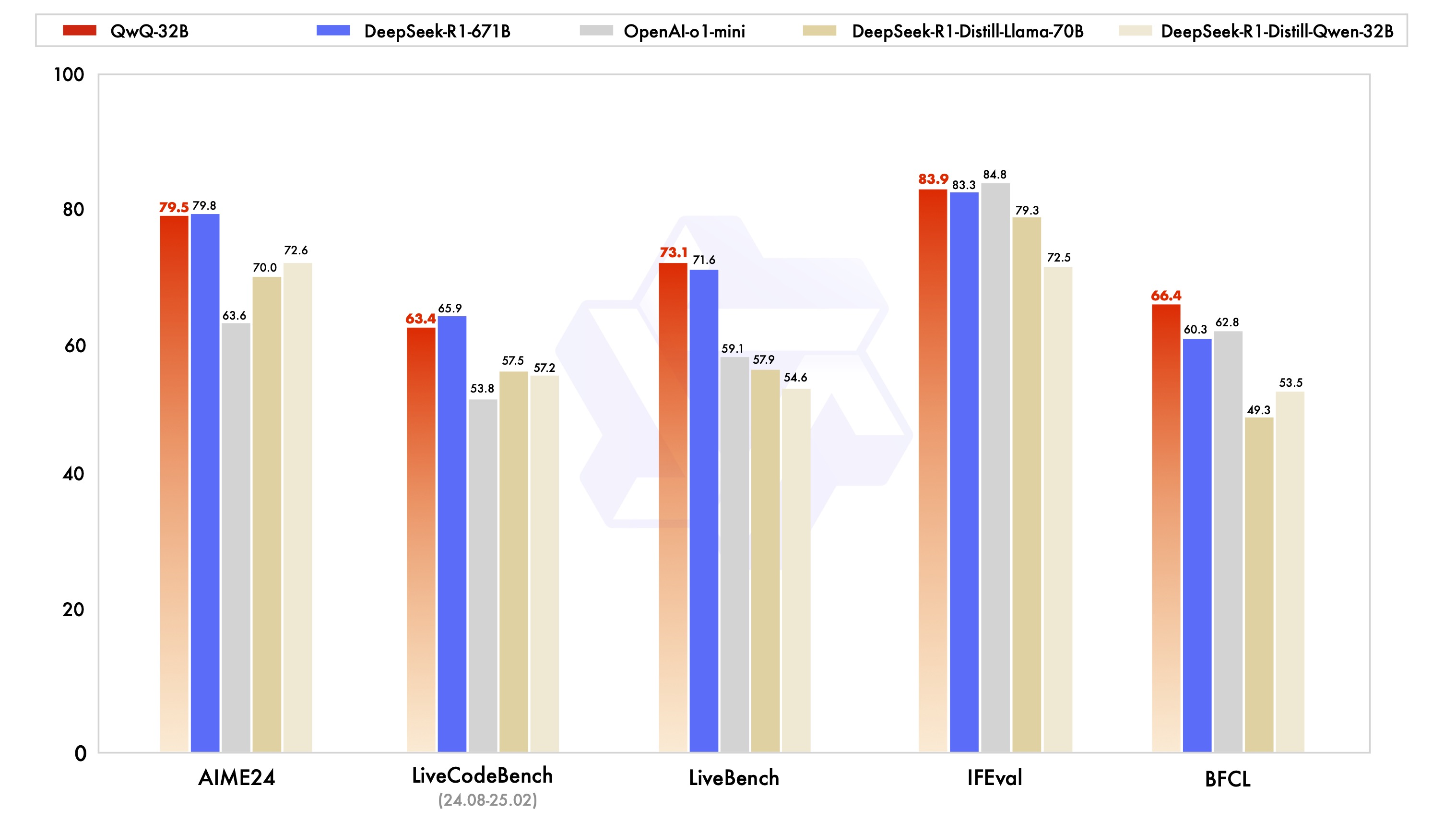
这张图与我个人的使用感受完全不同,比如拿出我经常使用的这个提示词
你是顶级的、参透世间万物发展规律的心理学家,用极短、极睿智方式解释四大终极人文关怀,如何理解死亡自由孤独无意义,100 字以内,输出 SVG 格式,3:4,小红书风格。

思考过程看起来是没有问题的,但最终呈现的结果,完全不可用。关闭预览模式重试,依然不理想。
我又测试了 Qwen 官网在 X 上的测试案例,与 Qwen-2.5-Max 对比。
感官上,不如 Max
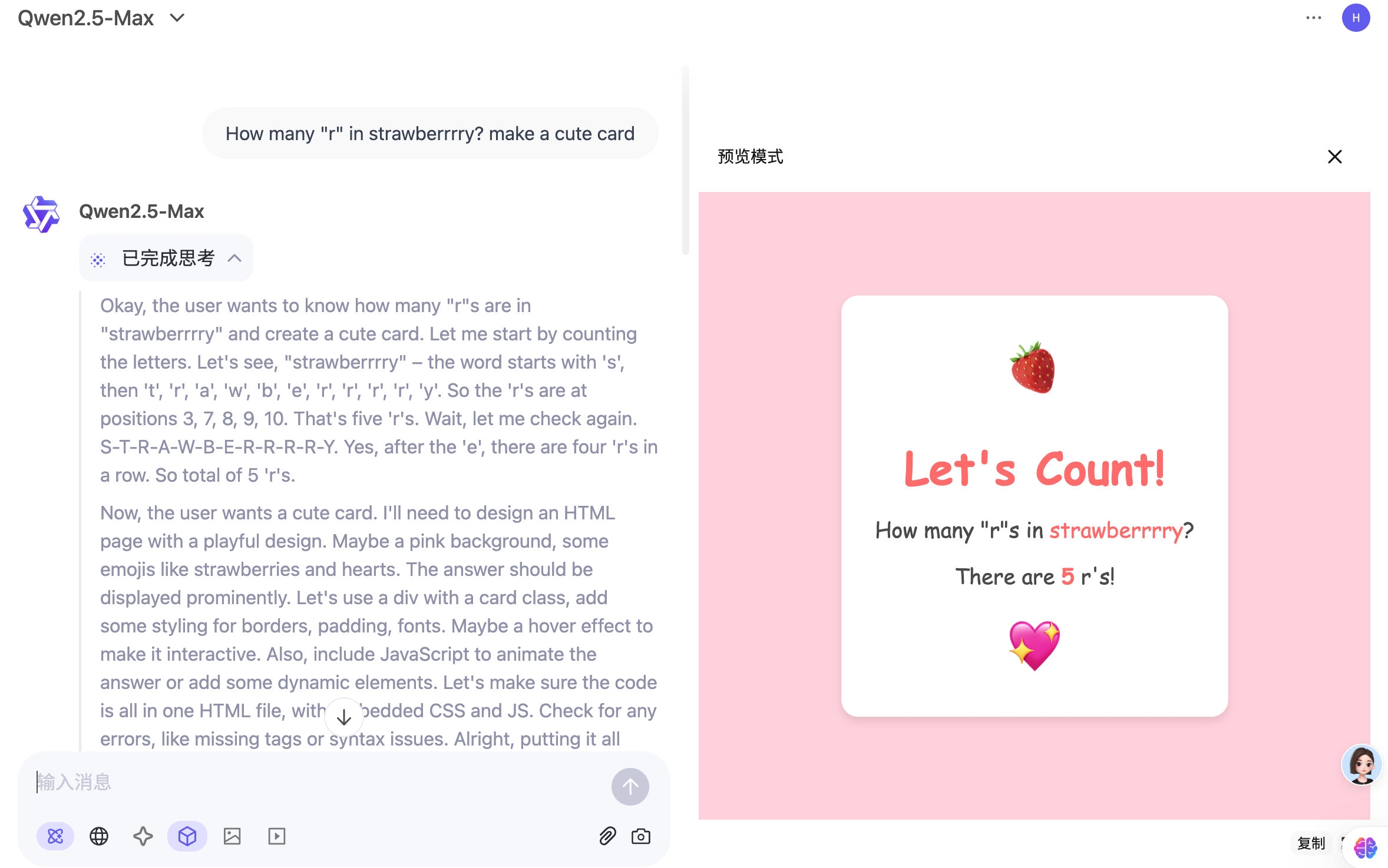
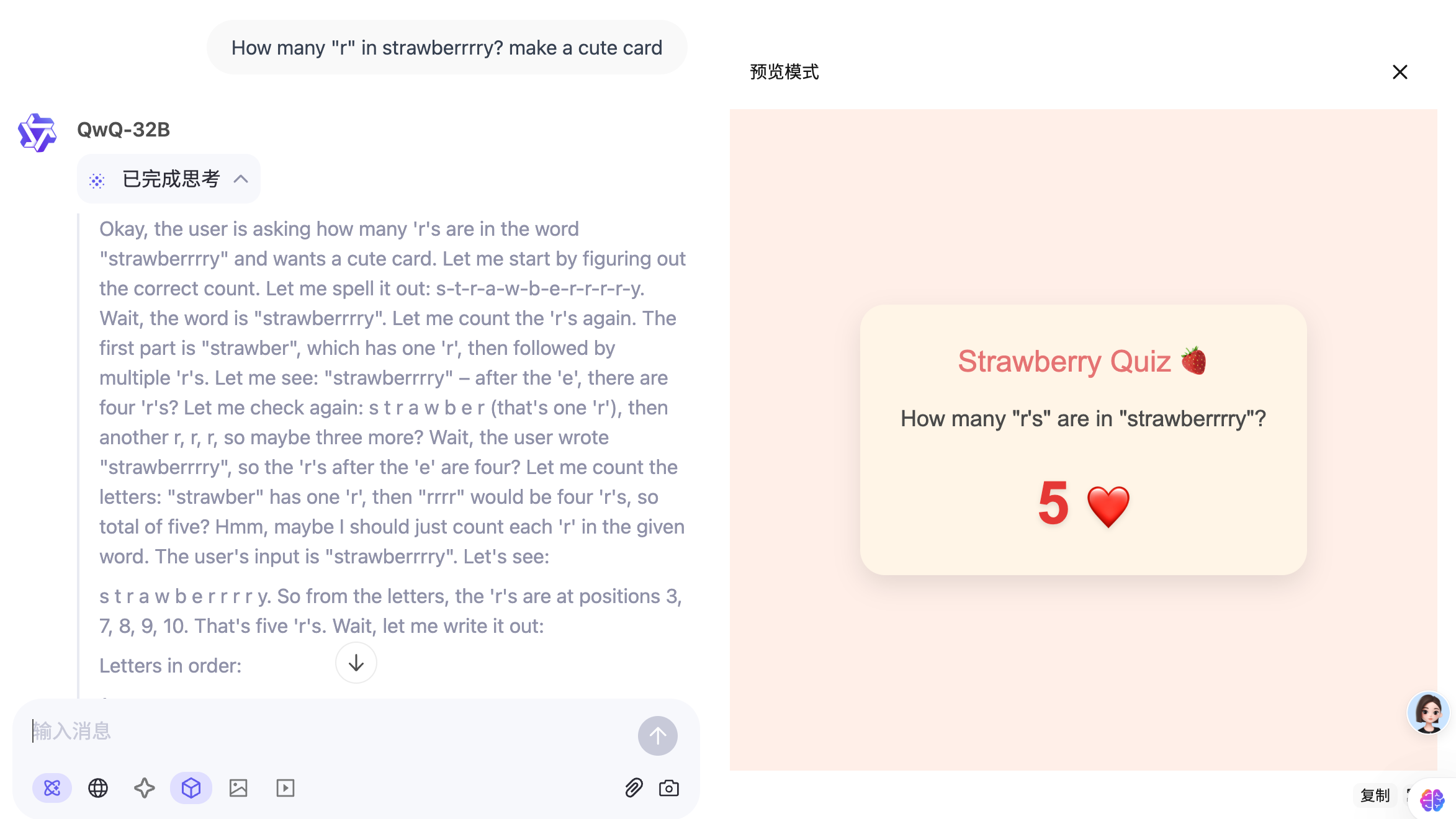
那 QwQ-32B 到底擅长什么?不擅长什么?这就不能个人感受了。
先看一个榜单:
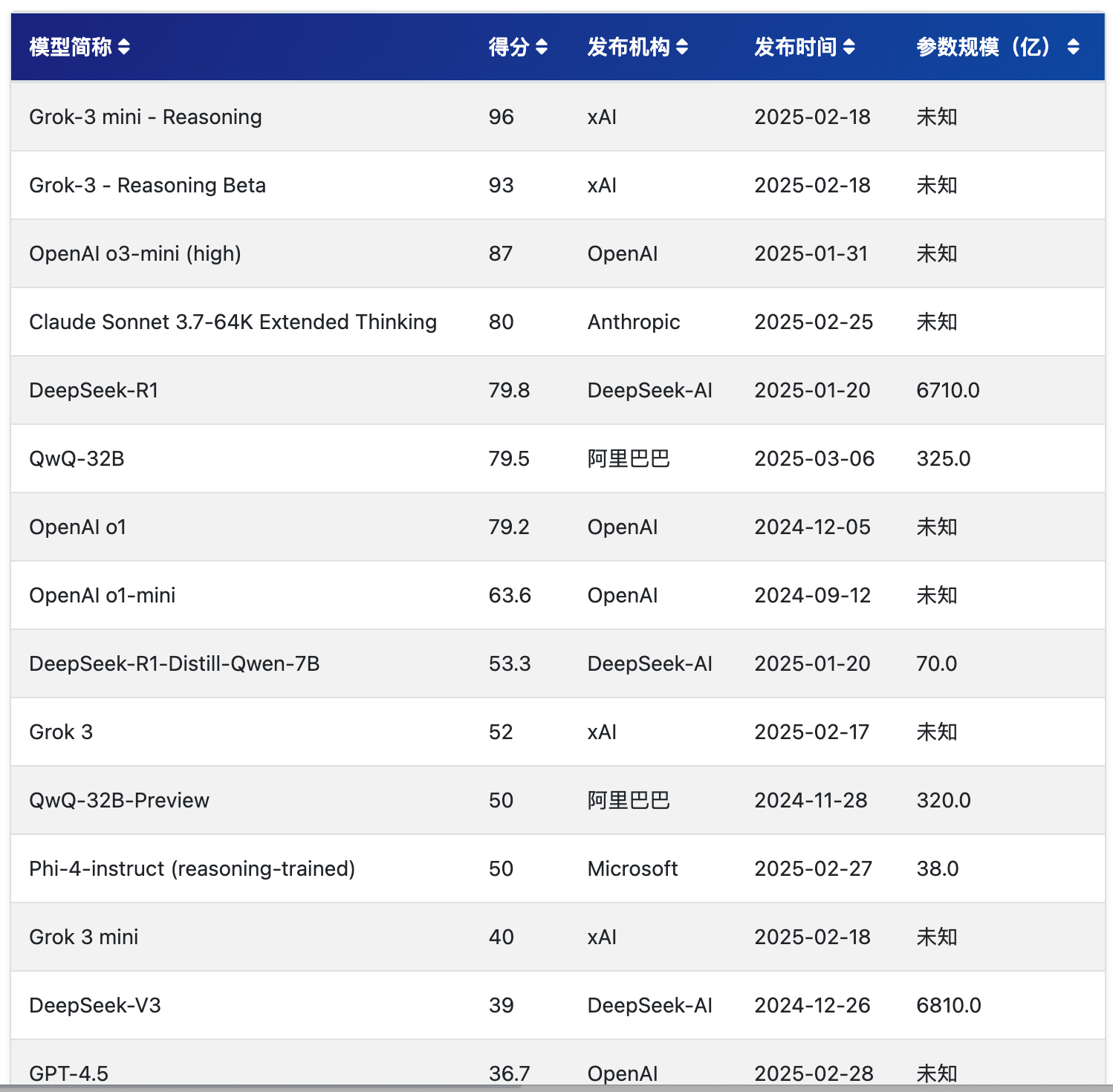 来自:https://www.datalearner.com/ai-models/llm-benchmark-tests/37
来自:https://www.datalearner.com/ai-models/llm-benchmark-tests/37
美国数学邀请赛(AIME)是面向中学生的邀请式竞赛,3 个小时完成 15 道题,难度很高,旨在考察顶尖高中生在各类数学领域的复杂问题解决能力。2024 年,AIME 成为评估大型语言模型数学推理能力的重要基准。
可以看出 QwQ-32B 能排第六名,阿里官方也引用了这个分数,看起来与 Grok-3 差距不少,和 DeepSeek-R1、Claude-3.7 差距不大。
还有另一个榜单
https://artificialanalysis.ai/
其数学能力与 AIME 有点出入,排名非常靠前。
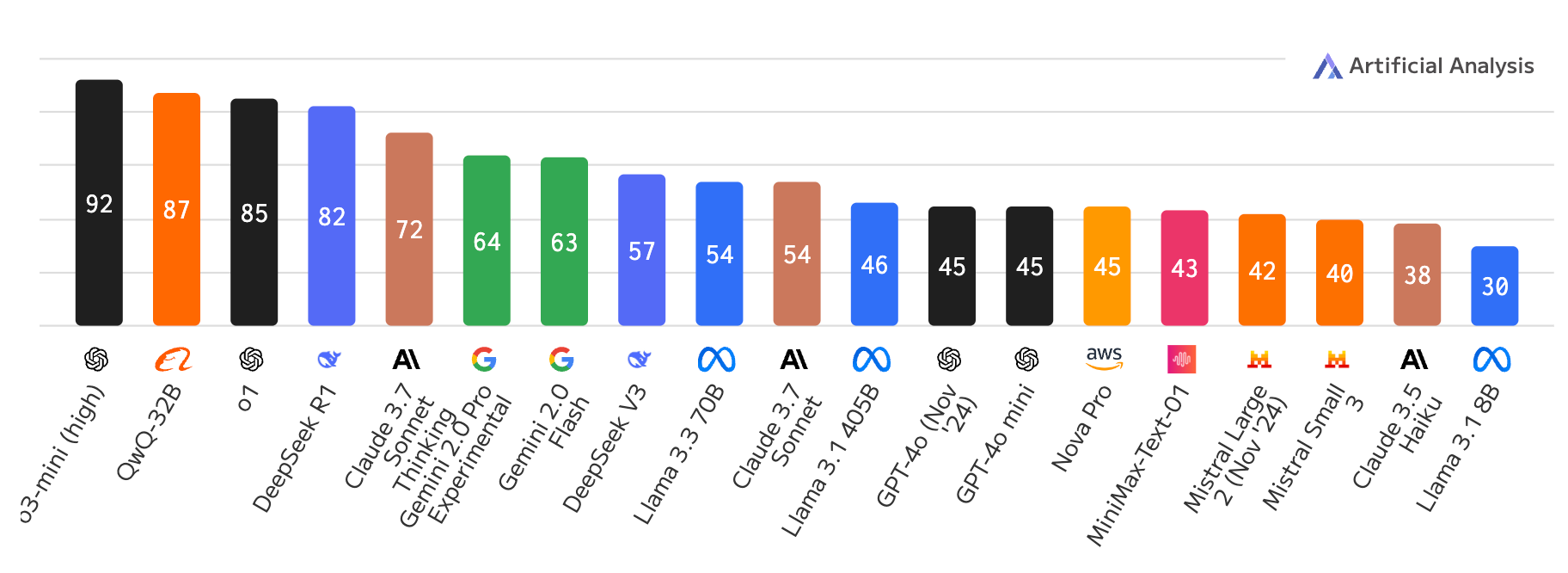
该榜单有一个智能指数包含涵盖推理、知识、数学和编码的七项评估,可以看出 QwQ-32B 综合实力也还可以。
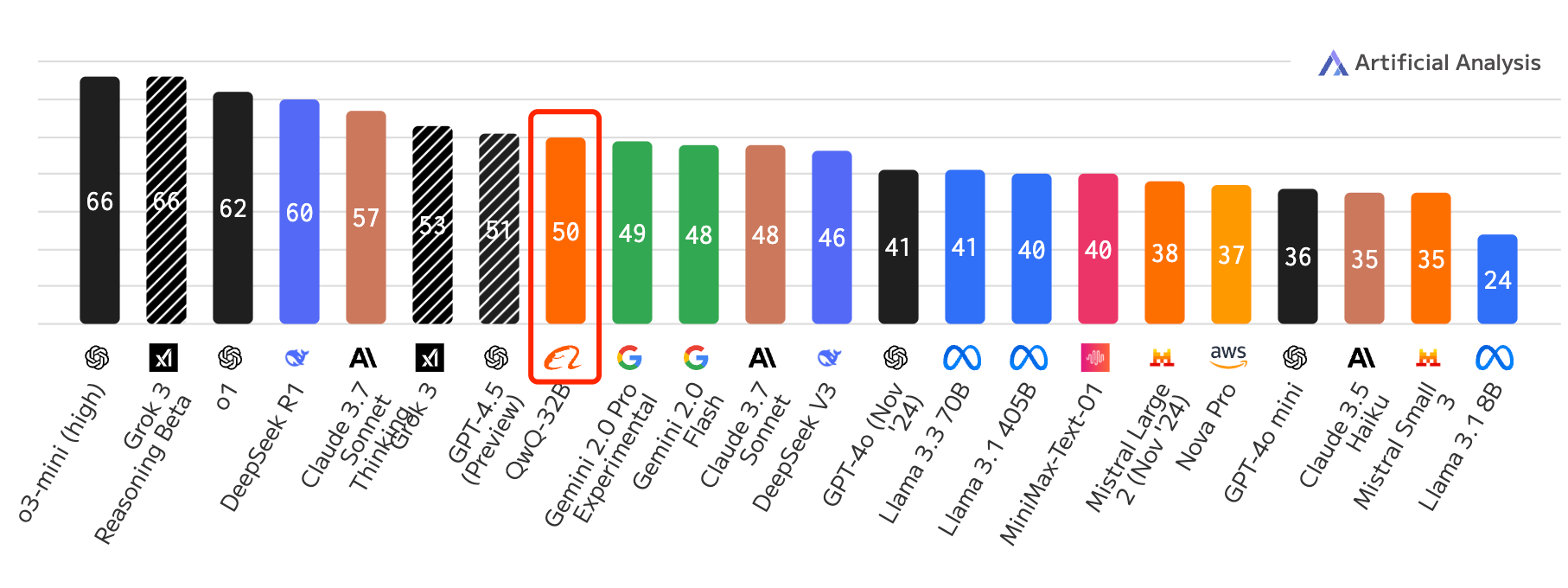 缺点是:它非常不擅长写代码
缺点是:它非常不擅长写代码
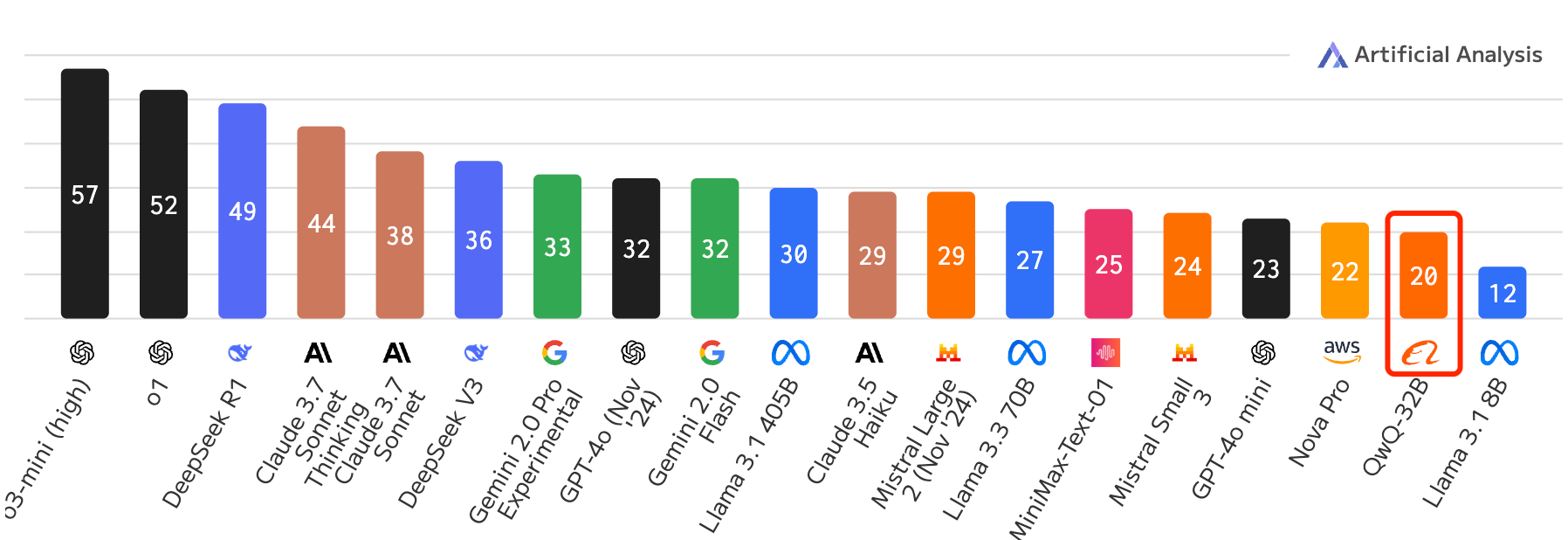
阿里在大模型开源这一块确实很有建树,比那么什么度强多了。
我的 Obsidian 还在把 Qwen/Qwen2.5-72B-Instruct-128K 当默认总结模型。
制作不易,如果这篇文章觉得对你有用,可否点个关注。给我个三连击:点赞、转发和在看。若可以再给我加个🌟,谢谢你看我的文章,我们下篇再见!
搭建完美的写作环境:工具篇(12 章)
图解机器学习 - 中文版(72 张 PNG)
ChatGPT、大模型系列研究报告(50 个 PDF)
108 页 PDF 小册子:搭建机器学习开发环境及 Python 基础
116 页 PDF 小册子:机器学习中的概率论、统计学、线性代数
史上最全!371 张速查表,涵盖 AI、ChatGPT、Python、R、深度学习、机器学习等
