大家好,我是老章
众所周知
使用大模型时,调用 API 总是不如网页版
其实,为了让 AI 模型更好地理解人类指令,提示词(Prompt)工程实际上包含 2 层核心内容,用户提示词(User prompt)和系统提示词(System prompt):
为了防止模型行为不当,各生成式 AI 厂商都会使用系统提示词(system prompts)来设定模型的基本行为准则,同时调整回复的语气和情绪。出于竞争和安全防护的考虑,这些提示词通常对外保密。
不过也有例外,比如 Anthropic 就开放了自家模型(Claude 3.5 Opus、Sonnet 和 Haiku)的系统提示词。
https://docs.anthropic.com/en/release-notes/system-prompts
Claude 的系统提示详细描述了模型如何处理各种任务和交互,包括如何应对数学问题、逻辑问题,如何处理包含人脸的图像,以及在面对争议话题时如何保持中立和客观。这些提示确保 Claude 在处理复杂问题时能够系统地思考,并以清晰、简明的方式提供信息。
最近 DeepSeek 也在 GitHub 公布了一系列 system prompt 和提示词相关技巧,对于需要基于本地部署或直接调用 API 开发大模型应用的开发者还是很有启发的。
技巧 1: 官方 DeepSeek 网页和 app 都没有内置系统提示词,因为所有指令都应当包含在用户提示(user prompt)中。
推理模型特别擅长处理信息有限或零散的情况,只需通过简单的提示词就能理解用户意图并妥善处理指令中的信息缺口。
技巧 2:将 Temperature 设置在 0.5-0.7(建议 0.6)的范围内,以防止无休止的重复或输出不一致。
技巧 3:搜索提示词
1
2
3
4
5
6
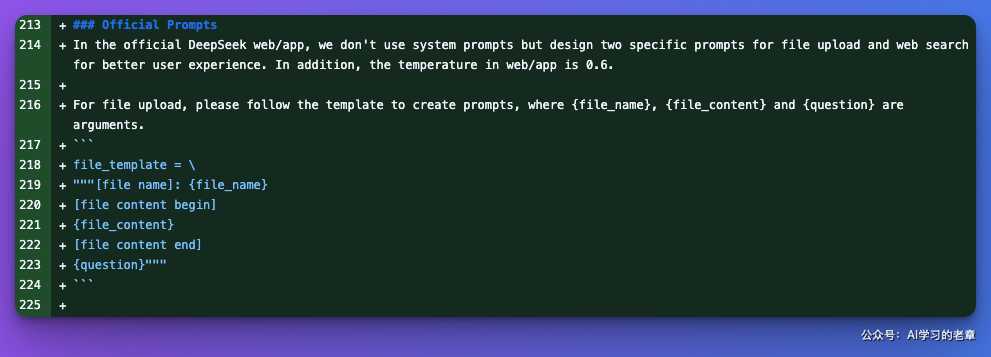
file_template = \
"""[file name]: {file_name}
[file content begin]
{file_content}
[file content end]
{question}"""
技巧 4:文件上传相关提示词
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
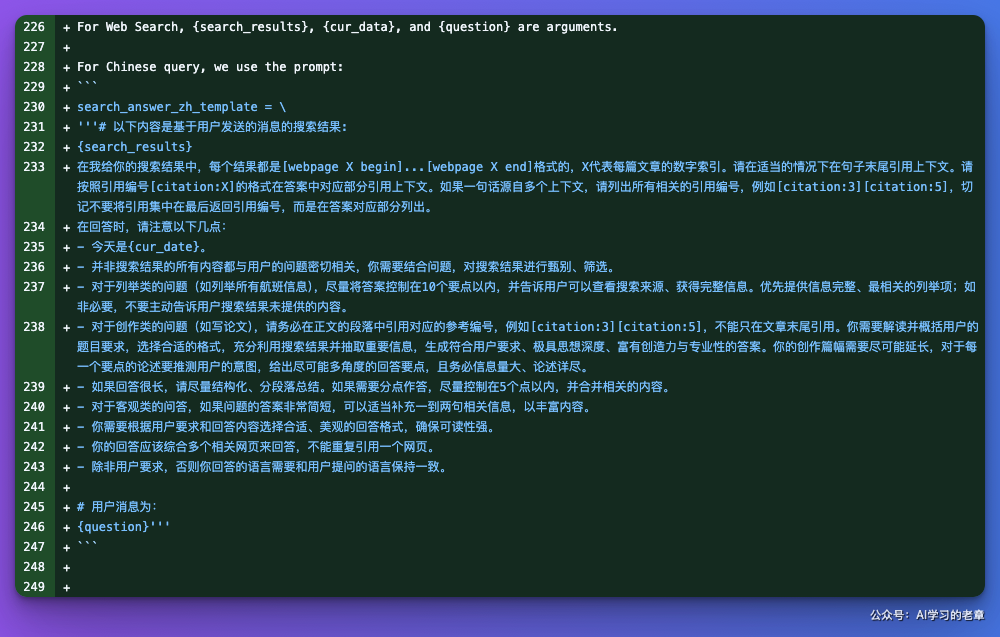
search_answer_zh_template = \
'''# 以下内容是基于用户发送的消息的搜索结果:
{search_results}
在我给你的搜索结果中,每个结果都是[webpage X begin]...[webpage X end]格式的,X代表每篇文章的数字索引。请在适当的情况下在句子末尾引用上下文。请按照引用编号[citation:X]的格式在答案中对应部分引用上下文。如果一句话源自多个上下文,请列出所有相关的引用编号,例如[citation:3][citation:5],切记不要将引用集中在最后返回引用编号,而是在答案对应部分列出。
在回答时,请注意以下几点:
- 今天是{cur_date}。
- 并非搜索结果的所有内容都与用户的问题密切相关,你需要结合问题,对搜索结果进行甄别、筛选。
- 对于列举类的问题(如列举所有航班信息),尽量将答案控制在10个要点以内,并告诉用户可以查看搜索来源、获得完整信息。优先提供信息完整、最相关的列举项;如非必要,不要主动告诉用户搜索结果未提供的内容。
- 对于创作类的问题(如写论文),请务必在正文的段落中引用对应的参考编号,例如[citation:3][citation:5],不能只在文章末尾引用。你需要解读并概括用户的题目要求,选择合适的格式,充分利用搜索结果并抽取重要信息,生成符合用户要求、极具思想深度、富有创造力与专业性的答案。你的创作篇幅需要尽可能延长,对于每一个要点的论述要推测用户的意图,给出尽可能多角度的回答要点,且务必信息量大、论述详尽。
- 如果回答很长,请尽量结构化、分段落总结。如果需要分点作答,尽量控制在5个点以内,并合并相关的内容。
- 对于客观类的问答,如果问题的答案非常简短,可以适当补充一到两句相关信息,以丰富内容。
- 你需要根据用户要求和回答内容选择合适、美观的回答格式,确保可读性强。
- 你的回答应该综合多个相关网页来回答,不能重复引用一个网页。
- 除非用户要求,否则你回答的语言需要和用户提问的语言保持一致。
# 用户消息为:
{question}'''
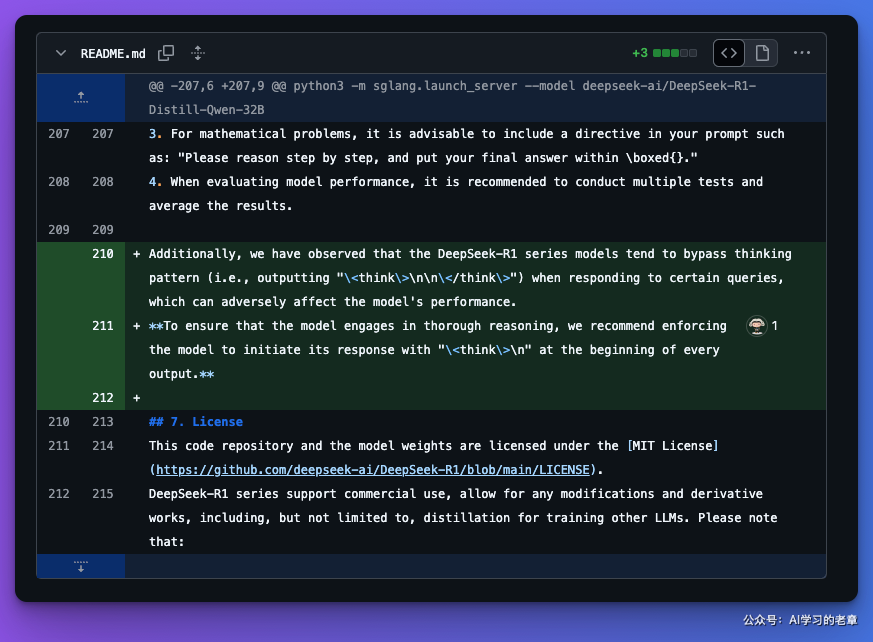
技巧 5:如何避免跳过思维模式
DeepSeek - R1 系列模型在响应某些查询时,往往会跳过思维模式(即输出“
**为确保模型进行全面推理,建议强制模型在每次输出开头以“
最后,到底如何撰写提示词,有一个比较务虚的解释,记得是 Claude 招聘主管分享的、对优秀提示工程师特质的见解:清晰沟通能力,能够准确地陈述事物、理解任务、思考和描述概念。