
大家好,我是章北海
高考结束了,前几天市面上有很多测评大模型在语文作文和高考数学的表现。
我凑热闹也测试了通义千问、Kimi、智谱清言、Gemini Advanced、Claude-3-Sonnet、GPT-4o
《国产大模型参加高考,同写2024年高考作文,及格分》
 文中,我设置了投票,观众评价这几个大模型谁“写”的作文最好。
文中,我设置了投票,观众评价这几个大模型谁“写”的作文最好。
收到了 106 个投票,GPT-4o 获55票,占比52%。

大模型的数学能力如何呢?
机器之心做了测试,我也转载这篇文章:高考数学,AI大模型被难倒,几乎全军覆没,GPT-4o仅得41 分
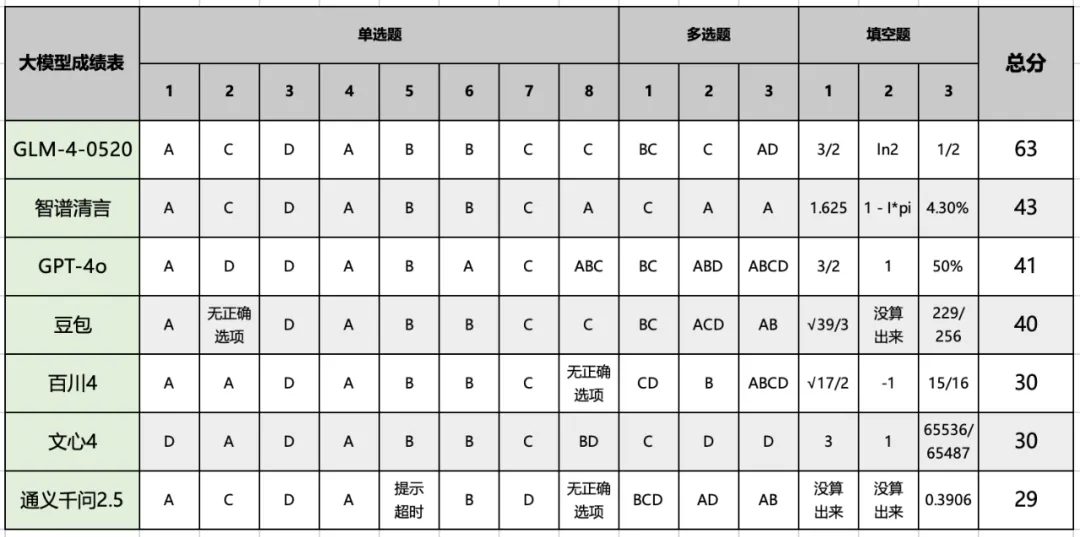
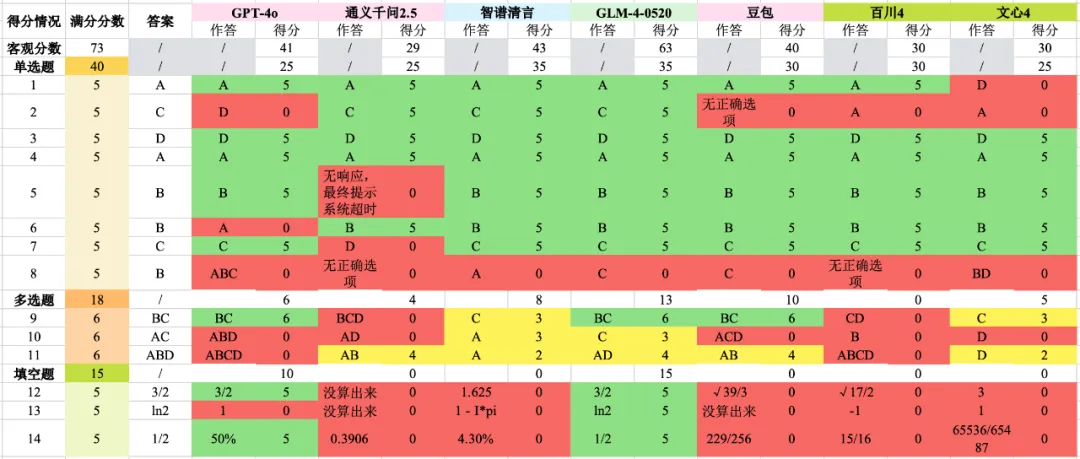
文中选择了GPT-4o、GLM-4、文心一言 4.0、豆包、百小应(百川 4)以及通义千问 2.5 去做高考数学考试(新课标 Ⅰ 卷)等试题。
机器之心评测了前 14 个客观题,覆盖了基础的数学知识和计算能力,满分为 73 分。
测试时,将题目直接输入,不做 System Prompt 引导,直接输出结果;同时也没有触发搜索,没有来自外界的干扰。
最终得分如下:
我对这个结果蛮惊讶的
一是各路大模型表现都很一般,客观题表现居然都这么差。
二是GPT-4o表现居然仅排第三,这和它在作文上的表现差远了。
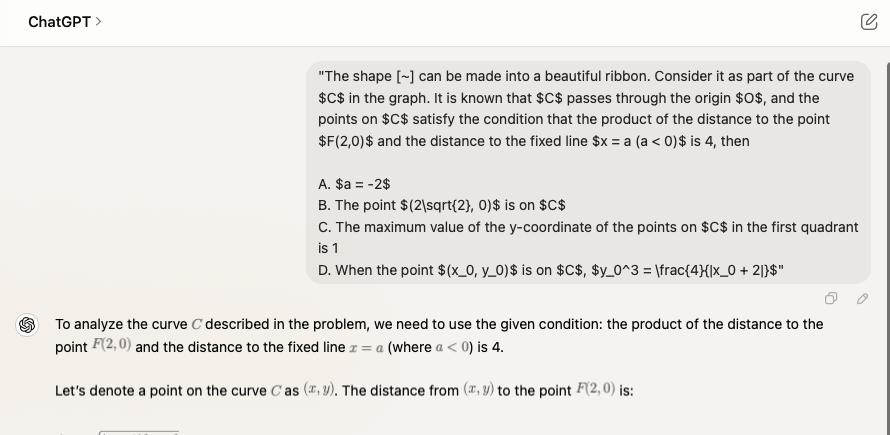
所以我有点好奇,如何把这GPT-4o做错的几道题用英语提问,结果会如何呢?
公平起见,也仅提问原题,不做Prompt引导。
单选题二:英文提问后回答正确✅


单选题六:英文提问后回答正确✅



单选题八:英文提问后回答依然错误❌


多选题二:英文提问后回答依然错误❌


多选题三:英文提问后回答依然错误❌

结论:
1、GPT-4o 用英文提问可以提升正确率,但有限。
2、国产大模型确实强,尤其是GLM-4,上周它还开源了,多模态能力比肩 GPT-4V。
3、大模型还是文科生,偏科严重,数学本身也是AI最难攻克的领域。
4、运用大模型应该扬长避短,要学会知“模型”而善用。