
Pandas是Python中一个强大的数据处理和分析库,特别适用于结构化数据。它提供了易于使用的数据结构和数据分析工具,使得处理和分析数据变得更加便捷和高效。

Pandas 开源库中包含 DataFrame,它是类似二维数组的数据表,其中每一列包含一个变量的值,每一行包含每列的一组值。熟悉用于统计计算的 R 编程语言的数据科学家和程序员都知道,DataFrame 是一种在易于概览的网格中存储数据的方法,这意味着 Pandas 主要以 DataFrame 的形式用于机器学习。

Pandas 允许导入和导出各种格式的表格数据,例如 CSV 或 JSON 文件。

Pandas 还允许各种数据操作操作和数据清理功能,包括选择子集、创建派生列、排序、连接、填充、替换、汇总统计和绘图。



虽然Pandas是一个功能强大的数据处理和分析库,但它也有一些缺点和局限性:
- 内存消耗大:
- Pandas在处理大型数据集时,会占用大量内存。因为Pandas会将整个数据集加载到内存中,这对于内存有限的系统可能会导致性能问题。
- 单线程限制:
- Pandas的大多数操作是单线程的,这意味着在处理大型数据集或复杂运算时,性能可能会受到限制。多线程和并行计算的支持较弱。
- 缺乏分布式计算:
- Pandas并不支持分布式计算,这使得在处理超大规模数据集时显得力不从心。对于这类任务,可以考虑使用Dask、Spark等支持分布式计算的框架。
- 性能瓶颈:
RAPIDS是一套英伟达开源的 GPU 加速 Python 库,旨在改进数据科学和分析流程。它是一个 GPU DataFrame 库,提供类似 pandas 的 API 用于加载、连接、聚合、过滤和以其他方式操作数据,无需深入了解 CUDA 编程的细节。
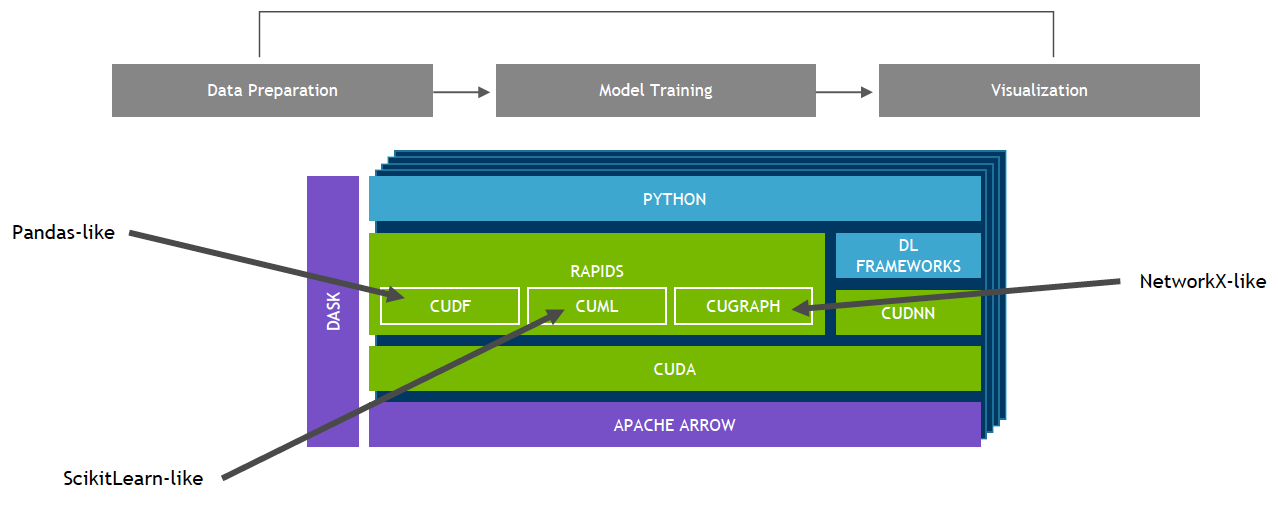
cuDF 可通过pipNVIDIA Python 软件包索引进行安装。请务必根据您的环境中可用的 CUDA 主要版本选择适当的 cuDF 软件包:
对于 CUDA 11.x:
1
pip install --extra-index-url=https://pypi.nvidia.com cudf-cu11
对于 CUDA 12.x:
1
pip install --extra-index-url=https://pypi.nvidia.com cudf-cu12
cuDF 可以使用 conda 安装(通过miniconda或来自以下频道的完整Anaconda 发行版rapidsai):
1
2
conda install -c rapidsai -c conda-forge -c nvidia \
cudf=24.08 python=3.11 cuda-version=12.2
要加速 IPython 或 Jupyter Notebooks,请使用以下魔法::
1
2
%load_ext cudf.pandas
import pandas as pd
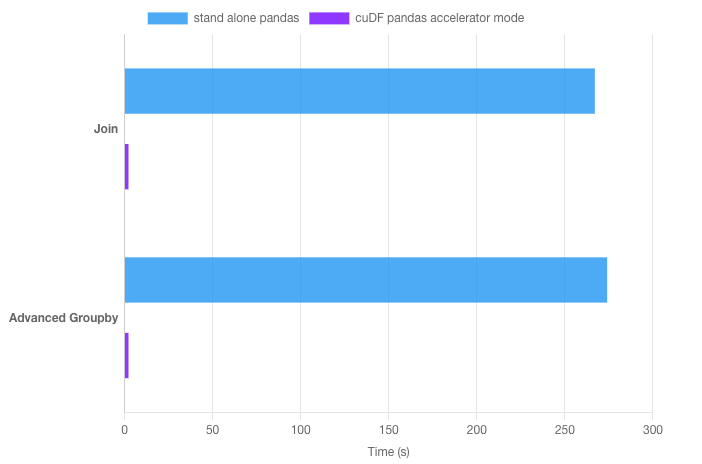
要加速 Python 脚本,请在命令行上使用 Python 模块标志:
python -m cudf.pandas script.py
或者,通过导入 cudf.pandas:
```import cudf.pandas
cudf.pandas.install()
import pandas as pd
1
2
3
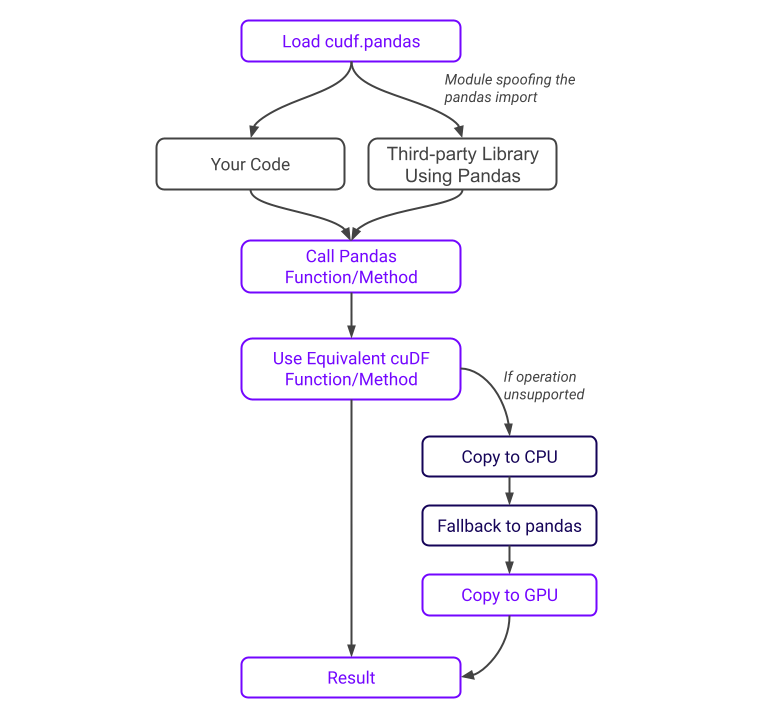
启用 cudf.pandas 后,import pandas(或其任何子模块)会导入一个魔法模块,而不是“常规”pandas。
In [1]: %load_ext cudf.pandas
In [2]: import pandas as pd
In [3]: pd
Out[3]: <module ‘pandas’ (ModuleAccelerator(fast=cudf, slow=pandas))>
```
参考:
https://github.com/rapidsai/cudf
docs.rapids.ai/api/cudf/stable/
https://www.nvidia.com/en-us/glossary/pandas-python/