
大家好,我是章北海
发现一个超强的Python库,创建大模型应用不能再简单
1
2
3
4
5
6
7
8
9
import gradio as gr
import ai_gradio
gr.load(
name='qwen:qwen1.5-14b-chat',
src=ai_gradio.registry,
title='AI Chat',
description='Chat with an AI model'
).launch()
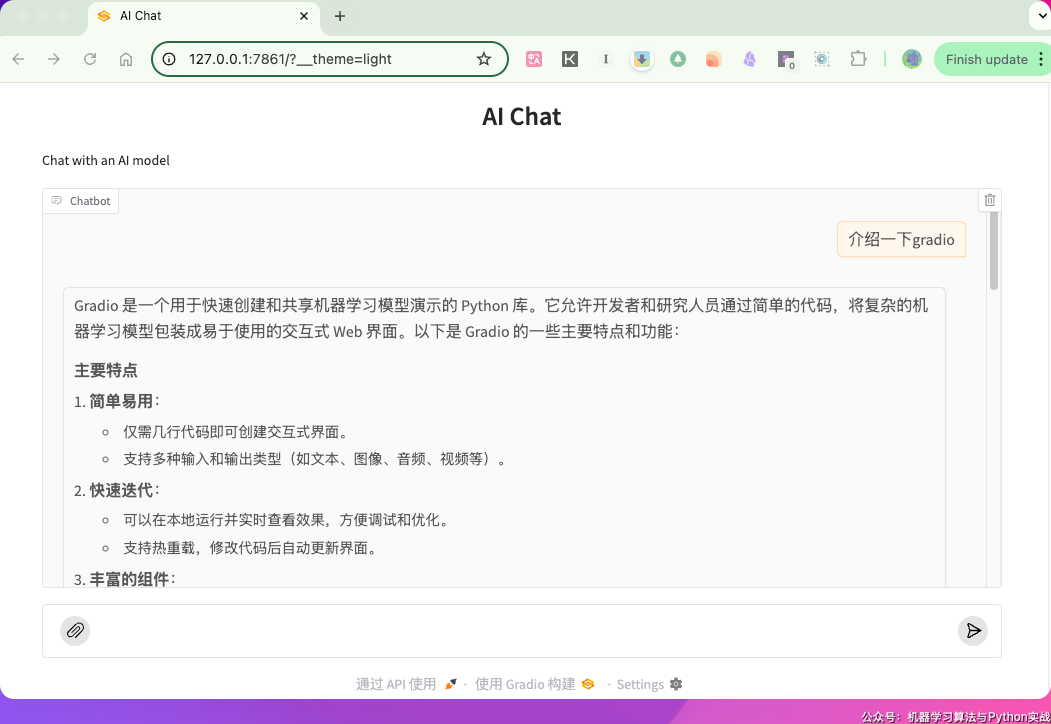
它还有语音聊天、视频聊天、相机模式、浏览器自动化等功能,功能强悍、使用极其简单。
项目地址:https://github.com/AK391/ai-gradio
ai–gradio 是一个 Python 包,可帮助开发者轻松创建由各种 AI 提供商支持的机器学习应用。它基于 Gradio 构建,为多个 AI 模型和服务提供统一接口。。
核心功能:
《多供应商支持》:可与 15 个以上的人工智能供应商集成,包括 OpenAI、Google Gemini、Anthropic 等。 《文本聊天》:为所有文本模型提供交互式聊天界面。 《语音聊天》:与 OpenAI 模型进行实时语音交互。 《视频聊天》:借助 Gemini 模型的视频处理能力。 《代码生成》:为编码辅助提供专门的界面。 《多模态》:支持文本、图像和视频输入。 《智能体团队》:与 CrewAI 集成以进行协作式人工智能任务。 《浏览器自动化》:能够执行基于网络任务的人工智能代理。
重要亮点
- 功能丰富:ai-gradio 提供多提供商支持,集成了 15 个以上的 AI 提供商,包括 OpenAI、Google Gemini、Anthropic 等。具有文本聊天、语音聊天、视频聊天、代码生成、多模态、代理团队、浏览器自动化等功能。
- 安装便捷:可以通过 pip 安装 ai-gradio 的核心包和特定提供商支持的包。有多种安装选项,如安装单个提供商支持、安装所有提供商等。
- 使用示例多样:提供了 API 密钥配置方法、快速入门示例和高级功能示例。包括创建不同类型的聊天界面、编码助手、多提供商界面、CrewAI 团队、浏览器自动化和 Swarms 集成等。
Core Language Models
| Provider | Models |
|---|---|
| OpenAI | gpt-4-turbo, gpt-4, gpt-3.5-turbo |
| Anthropic | claude-3-opus, claude-3-sonnet, claude-3-haiku |
| Gemini | gemini-pro, gemini-pro-vision, gemini-2.0-flash-exp |
| Groq | llama-3.2-70b-chat, mixtral-8x7b-chat |
Specialized Models
| Provider | Type | Models |
|---|---|---|
| LumaAI | Generation | dream-machine, photon-1 |
| DeepSeek | Multi-purpose | deepseek-chat, deepseek-coder, deepseek-vision |
| CrewAI | Agent Teams | Support Team, Article Team |
| Qwen | Language | qwen-turbo, qwen-plus, qwen-max |
| Browser | Automation | browser-use-agent |
安装很简单,pip install ai-gradio是必须的,还需要安装额外的大模型支持包,比如我只安装了pip install 'ai-gradio[deepseek]' 和 pip install 'ai-gradio[qwen]',省点事也可以一把梭哈pip install 'ai-gradio[all]'
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
# Install core package
pip install ai-gradio
# Install with specific provider support
pip install 'ai-gradio[openai]' # OpenAI support
pip install 'ai-gradio[gemini]' # Google Gemini support
pip install 'ai-gradio[anthropic]' # Anthropic Claude support
pip install 'ai-gradio[groq]' # Groq support
pip install 'ai-gradio[crewai]' # CrewAI support
pip install 'ai-gradio[lumaai]' # LumaAI support
pip install 'ai-gradio[xai]' # XAI/Grok support
pip install 'ai-gradio[cohere]' # Cohere support
pip install 'ai-gradio[sambanova]' # SambaNova support
pip install 'ai-gradio[hyperbolic]' # Hyperbolic support
pip install 'ai-gradio[deepseek]' # DeepSeek support
pip install 'ai-gradio[smolagents]' # SmolagentsAI support
pip install 'ai-gradio[fireworks]' # Fireworks support
pip install 'ai-gradio[together]' # Together support
pip install 'ai-gradio[qwen]' # Qwen support
pip install 'ai-gradio[browser]' # Browser support
# Install all providers
pip install 'ai-gradio[all]'
简单拿通义千问举个例
模型列表:https://bailian.console.aliyun.com/?spm=a2c4g.11186623.0.0.6f94b0a8AKJSUG#/model-market
API获取:https://bailian.console.aliyun.com/#/home
在控制台的右上角选择API-KEY,然后创建API Key,用于通过API调用大模型。
copy 后备用
题外话,通义千问api调用示例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
import os
from openai import OpenAI
client = OpenAI(
# 若没有配置环境变量,请用百炼API Key将下行替换为:api_key="sk-xxx",
api_key=os.getenv("DASHSCOPE_API_KEY"), # 如何获取API Key:https://help.aliyun.com/zh/model-studio/developer-reference/get-api-key
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
)
completion = client.chat.completions.create(
model="qwen-plus", # 模型列表:https://help.aliyun.com/zh/model-studio/getting-started/models
messages=[
{'role': 'system', 'content': 'You are a helpful assistant.'},
{'role': 'user', 'content': '你是谁?'}
]
)
print(completion.choices[0].message.content)
就ai_gradio例子,需要提前设置好api key
1
2
3
import os
os.environ["DASHSCOPE_API_KEY"] = "sk-上面复制好的"
其实ai-gradio还有窗口模式,同上,仅需提前备好api,就可以一个页面切换文本、图像、代码三模式使用。
1
2
3
4
5
6
7
8
9
10
11
12
import gradio as gr
import ai_gradio
with gr.Blocks() as demo:
with gr.Tab("Text"):
gr.load('openai:gpt-4-turbo', src=ai_gradio.registry)
with gr.Tab("Vision"):
gr.load('deepseek:deepseek-vision', src=ai_gradio.registry)
with gr.Tab("Code"):
gr.load('deepseek:deepseek-coder', src=ai_gradio.registry)
demo.launch()
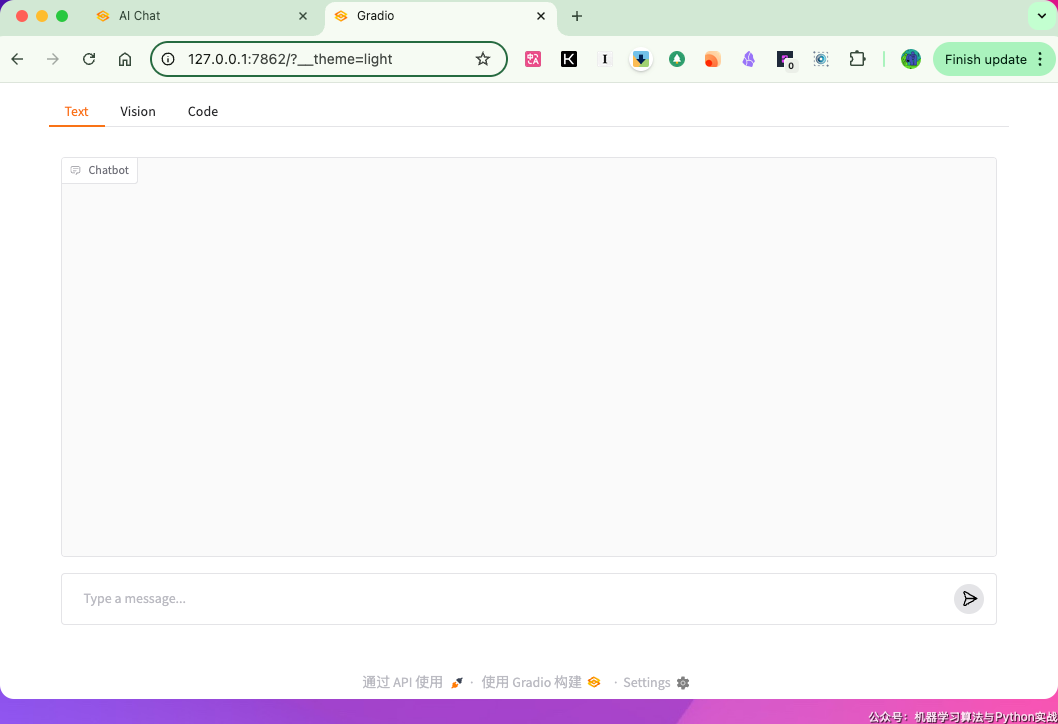
语音输入和相机模式我没有深入玩
简单试了一下
1
2
3
4
5
6
gr.load(
name='openai:gpt-4-turbo',
src=ai_gradio.registry,
enable_voice=True,
title='AI Voice Assistant'
).launch()
报错如下
1
2
3
4
5
6
7
8
9
10
11
12
HTTP Error Your request was:
POST /Accounts/None/Tokens.json
Twilio returned the following information:
Unable to create record: Authentication Error - No credentials provided
More information may be available here:
https://www.twilio.com/docs/errors/20003
找了原因,camera和voice都依赖browser-use
项目地址: https://github.com/browser-use/browser-use
我看官方示例,感觉蛮强的,有机会再试
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
import asyncio
import os
from langchain_ollama import ChatOllama
from browser_use import Agent
async def run_search():
agent = Agent(
task=(
'1. Go to https://www.reddit.com/r/LocalLLaMA'
"2. Search for 'browser use' in the search bar"
'3. Click search'
'4. Call done'
),
llm=ChatOllama(
# model='qwen2.5:32b-instruct-q4_K_M',
# model='qwen2.5:14b',
model='qwen2.5:latest',
num_ctx=128000,
),
max_actions_per_step=1,
tool_call_in_content=False,
)
await agent.run()
if __name__ == '__main__':
asyncio.run(run_search())
[[obsidian://open?vault=zhangAI&file=Wechat%2F389458132-171fb4d6-0355-46f2-863e-edb04a828d04.mp4]]